Group Details Private
administrators
Member List
-
HungBui
posted in Monkey Stories 2.0 • read moreCác bước thực hiện để có thể build game cho QA thông qua hệ thống Tool Game
Bước 1: Switch git branch
Sử dụng branch feature/build_qa để có thể build gameBước 2: Merger code
Merger code của nhánh đang dev game vào nhánh feature/build_qa sau đó commit lên.Bước 3: Setup thêm game vào tool manager
Setup như hướng dẫn tại đâyBước 4: Commit lên branch feature/build_qa
Bước 5: Build bằng CI/CD
Sử dụng CI/CD để hoàn thành build5.1 Yêu cầu thêm vào nhóm telegram CI_Monkey Stories để nhận thông báo build:
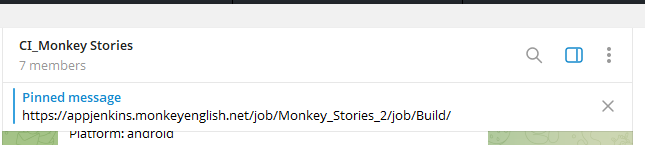
5.2 Đăng nhập link được ghim trên nhóm để vào giao diện CI/CD build android hoặc ios
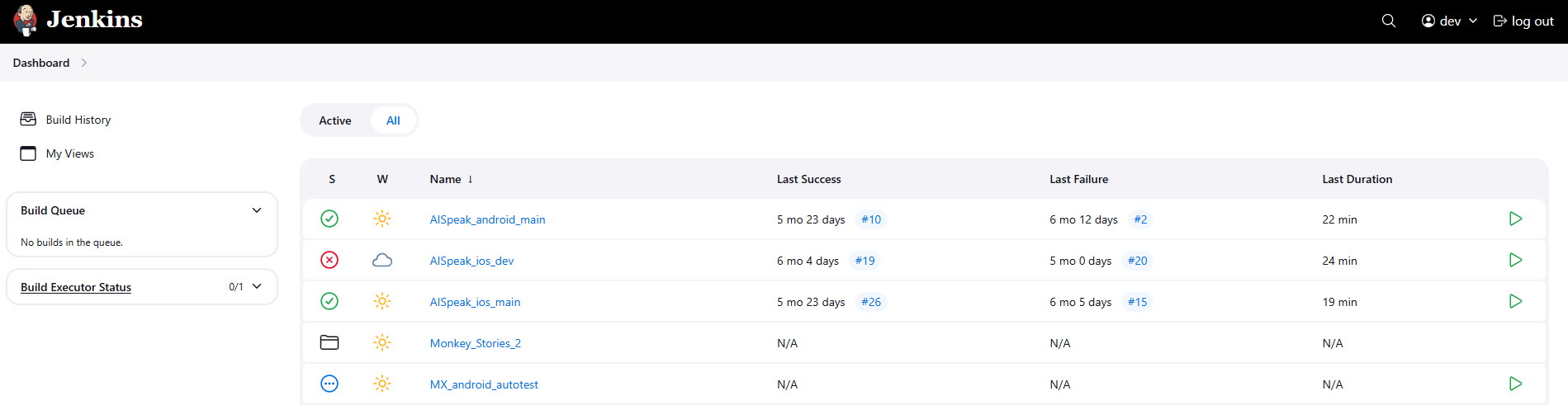
5.3 Chọn vào thư mục Monkey_Stories_2 để ra khu vực build cho MS 2.0
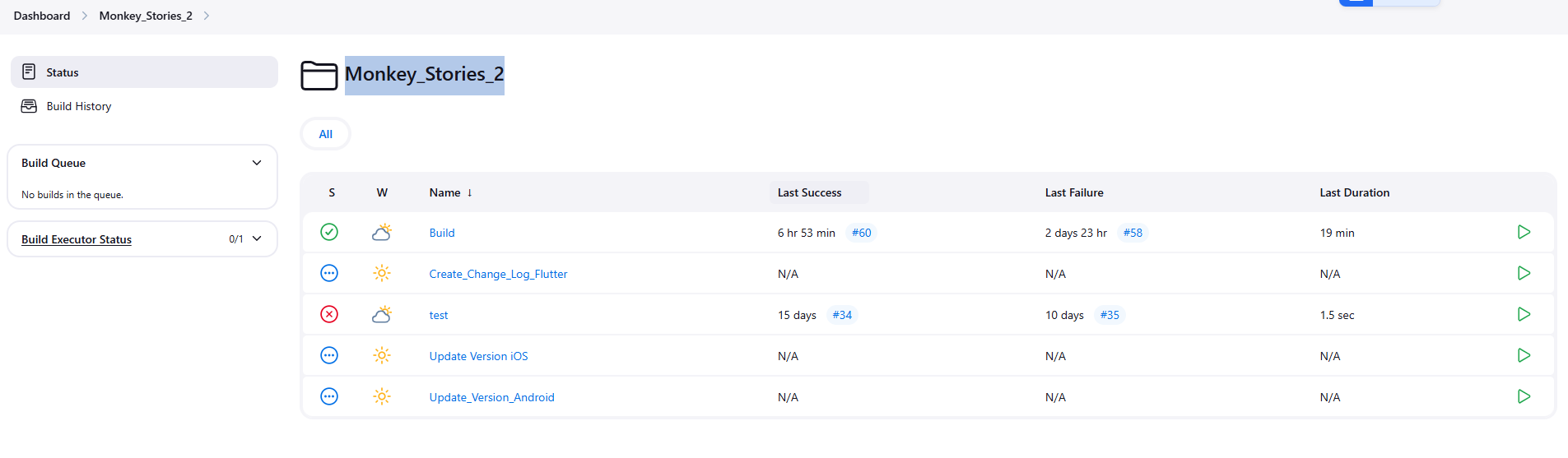
5.4 Chọn Build
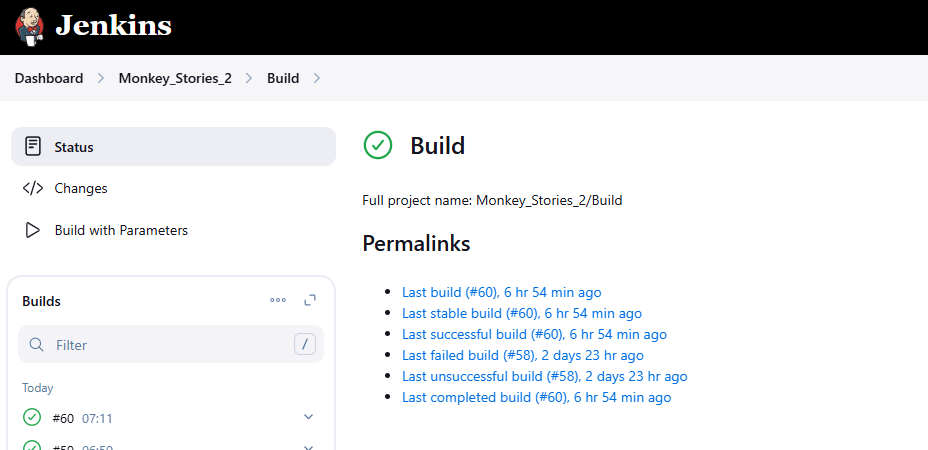
5.5 Chọn Build with parammeters
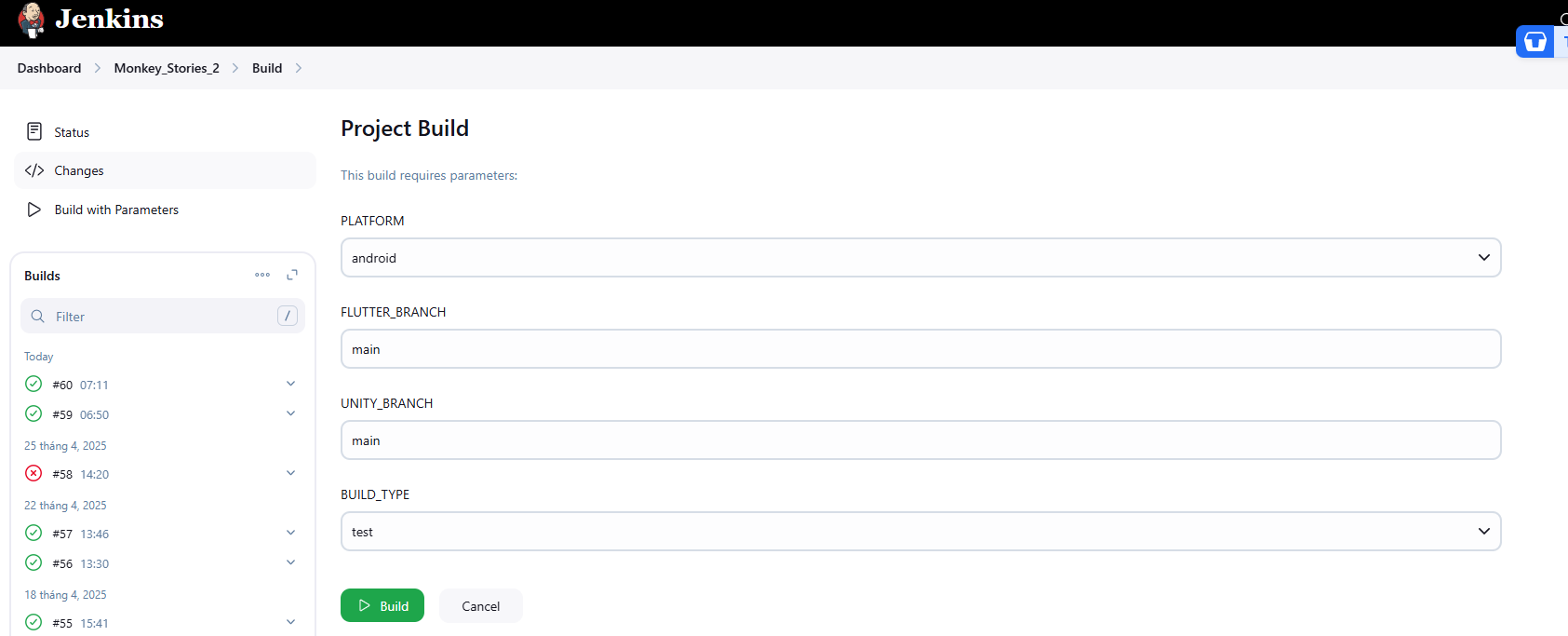
5.6 Lựa chọn thông số- PLATFORM : build cho android / ios
- FLUTTER_BRANCH : tên branch của vỏ app (hỏi dev app để biết đúng nhánh)
- UNITY_BRANCH : điền feature/build_qa
5.7 Bấm Build
Bước 6: Theo dõi thông báo và trạng thái build từ nhóm telegram CI_Monkey Stories
-
trunghoang12
posted in Data_team • read moreTài liệu dự án Text2SQL
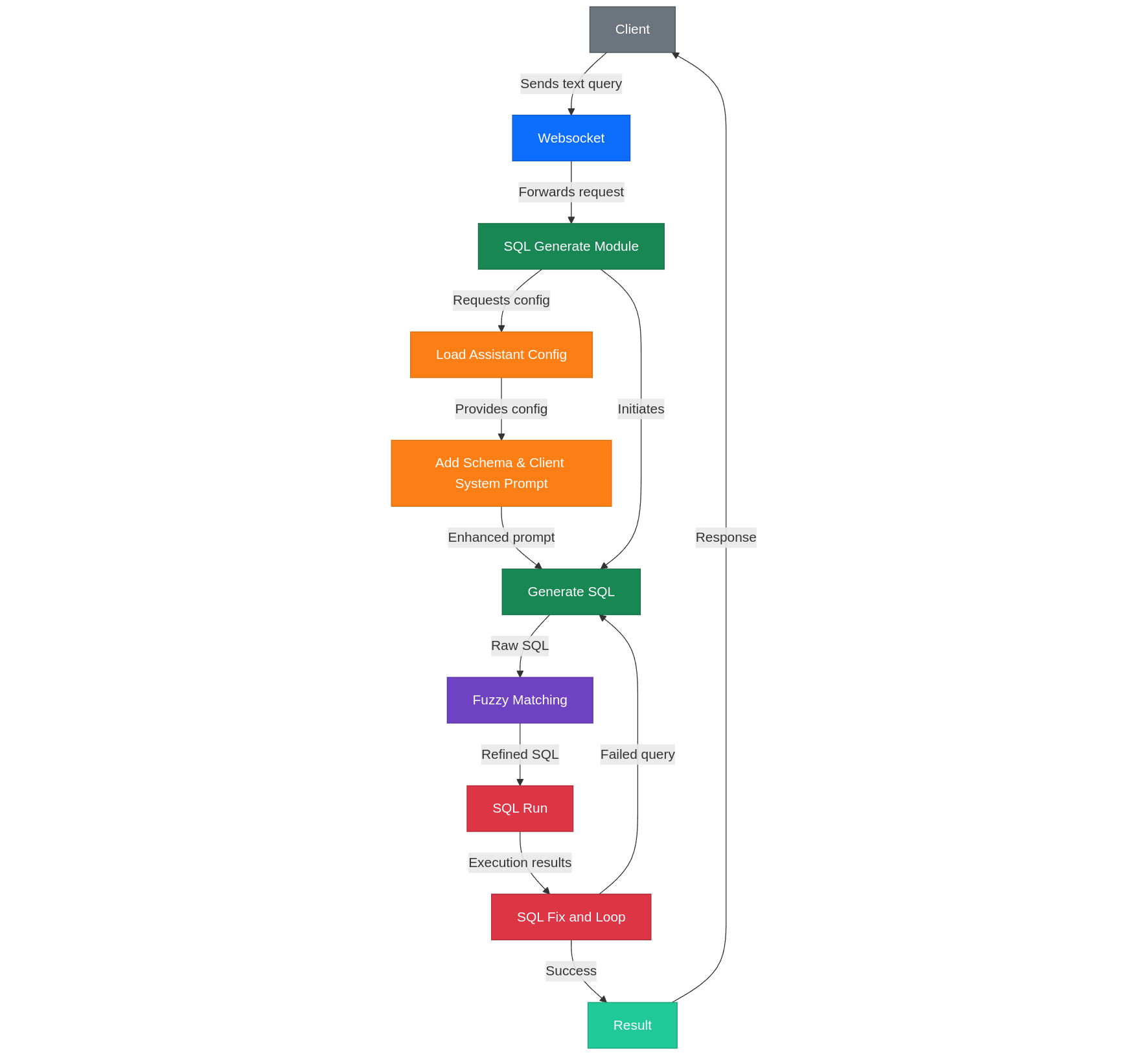
1. Sơ đồ tổng quan hệ thống
Luồng sử dụng
Khởi tạo:
- Tạo data group: Người dùng chọn danh sách table và columns trong Redshift thông qua giao diện web
- Tạo chatbot: Người dùng tạo chatbot với data group đã chọn
- Đăng nhập: Web sử dụng xác thực Google kết nối với email CRM của Monkey
Sử dụng:
- Chat và truy vấn: Người dùng tương tác với chatbot để truy vấn dữ liệu trên data group đã chọn
- Hiệu chỉnh schema: Người dùng có thể đọc và sửa schema nếu cần để nâng cao độ chính xác
Luồng Text2SQL
Kết nối:
- Client → WebSocket → Server → SQL Module
SQL Module:
- Data Group Selection: Lựa chọn nhóm dữ liệu để truy vấn
- SQL/Code Generation: Sinh mã SQL dựa trên văn bản đầu vào
- Fuzzy Search: Sửa giá trị một số trường thông qua tìm kiếm fuzzy
- Run và Feedback: Thực thi SQL và cung cấp phản hồi
Xử lý bất đồng bộ:
- Sử dụng Redis Queue để thực thi SQL, tránh block luồng chính
- Mỗi trạng thái khi chạy được stream về phía client qua WebSocket
Lưu trữ:
- Lịch sử chat được lưu vào MongoDB, collection
edu_backend.user_chat_logs
Cấu trúc dữ liệu chat trong MongoDB:
{ "_id": { "$date": "2024-12-31T11:35:41.510Z" }, "updated_at": { "$date": "2024-12-31T11:35:41.510Z" }, "message_count": 0, "is_active": true, "is_archived": false, "tags": [], "metadata": {} }Công nghệ sử dụng:
- Backend: Python FastAPI
- Xác thực: Google OAuth
- Queue xử lý: Redis Queue
- Cơ sở dữ liệu:
- Nguồn dữ liệu chính: Redshift
- Lưu trữ cấu hình và chat: MongoDB
- Giao thức kết nối: WebSocket
2. Sơ đồ xử lý Text2SQL
-
posted in Base • read more
Mục tiêu
Thống nhất về cùng kiểu endgame
Tiết kiệm thời gian phát triển endgame trong quá trình dev gameTổ chức
updating...
Cách dùng
Kéo prefabs endgame trong Base lên Hierarchy như hình
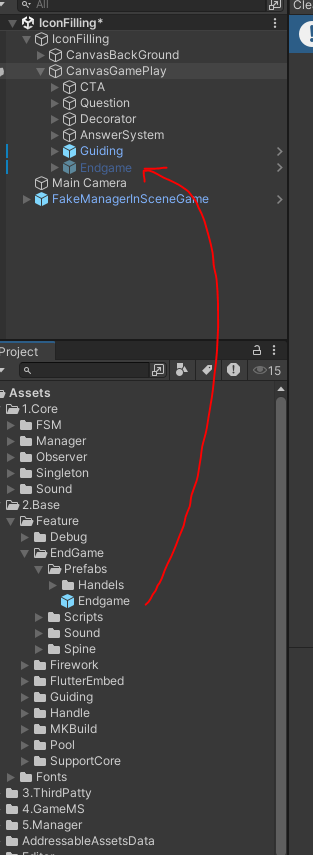
Set Active false trên Hierarchy
Reference vào đối tượng cần dùng

Chú ý sử dụng tính abstraction
Call các method tương ứng

Chú ý bỏ âm thanh yeah kết thúc của game nếu có (Sẽ có yêu cầu từ GD)
Các phương thức hỗ trợ
- Scale: Thay đổi kích thước của hướng dẫn.
- SetActive: Ẩn hiện endgame.
- SetPosition: Vị trí của end game nhưng thường sử dụng (0,0).
- SetParent: Ít khi sử dụng.
- PlayAnimation: Phát Anim, chú ý đến các action end game .
Xin hãy đọc thêm ở summary của từng method
-
posted in Data_team • read more
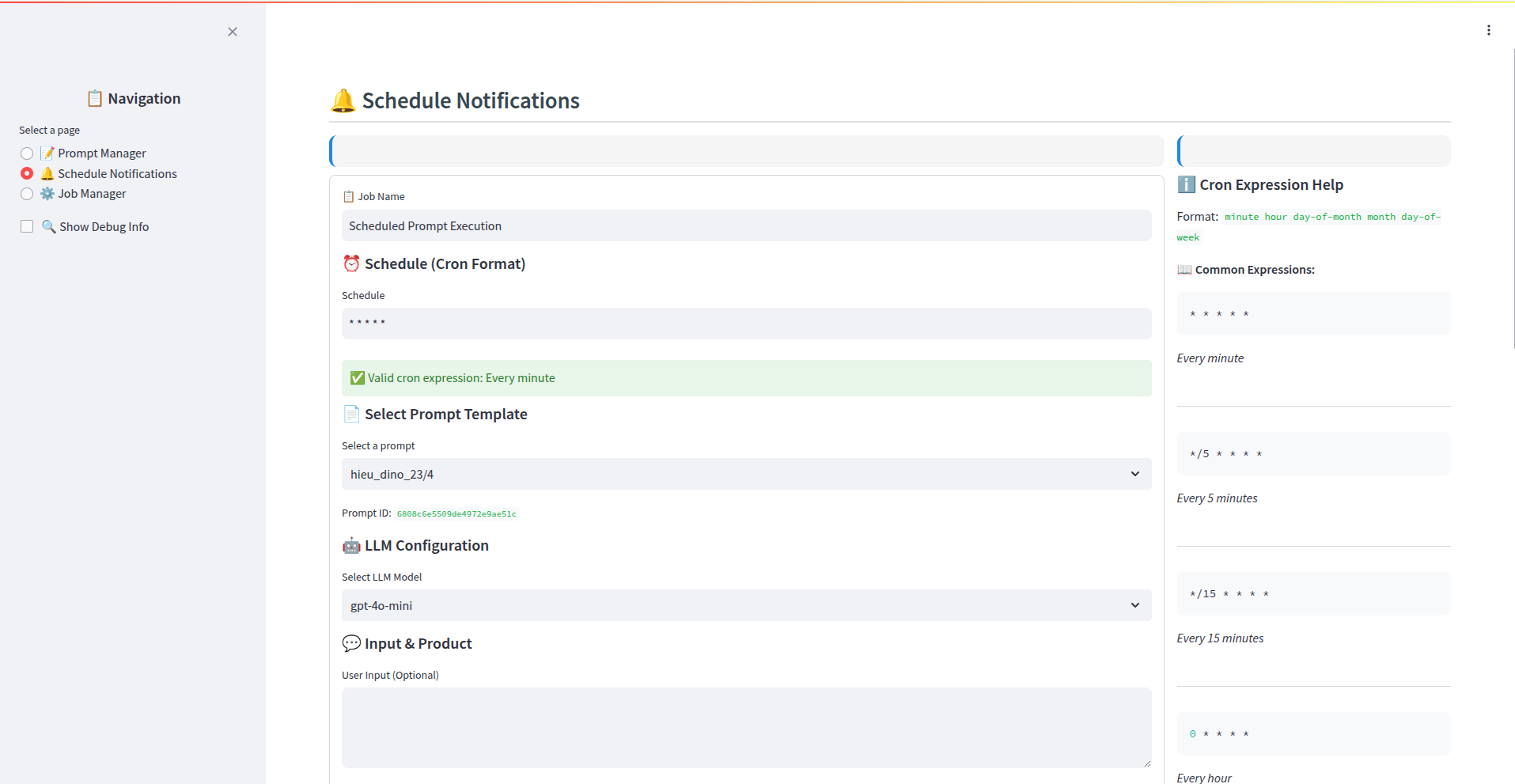
Mô Tả Luồng: Lập Lịch & Gửi Thông Báo AI-Powered qua Firebase
Luồng này mô tả quy trình từ việc tạo nội dung thông báo bằng AI, lên lịch gửi, xử lý bởi backend, gửi qua Firebase và theo dõi kết quả.
Giai đoạn 1: Tạo Prompt Thông Báo
- Người dùng (Admin/Content Creator): Truy cập giao diện người dùng (UI) tại
https://github.com/eduhub123/edu_scheduler_notifier/tree/master/front-end. - Tạo Prompt:
- Sử dụng trình soạn thảo hoặc các trường nhập liệu trên UI để định nghĩa template cho prompt.
- Tham khảo các template có sẵn trong UI để có cấu trúc phù hợp.
- QUAN TRỌNG: Đảm bảo nội dung prompt khi được AI xử lý sẽ tạo ra kết quả có định dạng chính xác:
Title: <Nội dung tiêu đề thông báo> Body: <Nội dung chi tiết thông báo>
3. Lưu Prompt:
* Sau khi hoàn tất, người dùng lưu prompt lại.
* Hệ thống (Backend Go): Nhận yêu cầu lưu prompt.
* Lưu trữ (MongoDB): Thông tin cấu hình prompt (template, tên, các tham số liên quan) được lưu vào collectionedu_backend.go_prompts.Giai đoạn 2: Tạo và Lập Lịch Job Gửi Thông Báo
-
Người dùng (Admin/Scheduler): Truy cập giao diện quản lý Lập lịch (Scheduler UI - có thể là một phần của front-end trên).
-
Tạo Job Mới:
- Chọn Prompt đã tạo ở Giai đoạn 1 để sử dụng cho job này.
- Chọn Ứng Dụng (App): Chỉ định rõ thông báo này sẽ được gửi đến người dùng của ứng dụng nào (ví dụ: App Học Sinh, App Giáo Viên).
- Cấu hình Lịch trình: Đặt thời gian gửi (gửi ngay, gửi một lần vào thời điểm cụ thể, gửi định kỳ - ví dụ: hàng ngày, hàng tuần).
- Cấu hình Đối tượng (Segmentation): Định nghĩa tiêu chí để lọc danh sách người dùng/thiết bị nhận thông báo (ví dụ: query dựa trên lớp học, khóa học đã đăng ký, hoạt động gần đây...).
- Cấu hình Hành động (Actions):
- QUAN TRỌNG: Trong danh sách các hành động có thể thực hiện, chọn chính xác
send_notification_for_a_segmentation_device. Hành động này chỉ định job sẽ gửi thông báo Firebase đến một nhóm người dùng đã được phân đoạn.
- QUAN TRỌNG: Trong danh sách các hành động có thể thực hiện, chọn chính xác
-
Lưu và Kích hoạt Job:
- Người dùng lưu cấu hình job.
- Người dùng kích hoạt (activate) job để đưa vào trạng thái sẵn sàng chạy theo lịch.
- Hệ thống (Backend Go): Nhận yêu cầu lưu và kích hoạt job.
- Lưu trữ (MongoDB): Thông tin cấu hình job (ID prompt, lịch trình, query phân đoạn, app target, trạng thái
activate...) được lưu vào collectionedu_backend.schedule_jobs.
Giai đoạn 3: Xử Lý Job và Gửi Thông Báo (Tự động bởi Backend)
-
Scheduler Trigger (Backend Go): Dựa trên lịch trình đã cấu hình trong
schedule_jobs, hệ thống Go xác định job nào cần chạy tại thời điểm hiện tại (job có trạng tháiactivatevà đúng giờ). -
Lấy Thông Tin Job: Hệ thống truy xuất thông tin chi tiết của job cần chạy từ
edu_backend.schedule_jobs. -
Xử lý Prompt với AI:
- Lấy template prompt từ
edu_backend.go_promptsdựa trên ID prompt trong job. - Gọi API của AI Model đã cấu hình (Gemini hoặc OpenAI GPT) với template prompt làm đầu vào.
- Nhận kết quả từ AI là nội dung thông báo hoàn chỉnh theo định dạng
Title:vàBody:.
- Lấy template prompt từ
-
Phân Đoạn Người Dùng (Segmentation):
- Thực thi query phân đoạn (đã định nghĩa trong job) trên cơ sở dữ liệu người dùng/thiết bị để lấy danh sách các Firebase device token của những người dùng thỏa mãn điều kiện.
-
Chia Batch Token:
- Kiểm tra giới hạn Firebase: Hệ thống biết rằng Firebase có giới hạn gửi (ví dụ: 500 token/request).
- Nếu danh sách token lấy được lớn hơn giới hạn, hệ thống sẽ chia danh sách này thành nhiều batch nhỏ hơn (mỗi batch tối đa 500 token).
-
Đưa Batch vào Hàng Đợi (Queue):
- Từng batch token được đưa vào một hàng đợi (queue) nội bộ do Go quản lý. Việc này giúp xử lý gửi tuần tự và tránh quá tải.
-
Gửi Thông Báo Từng Batch:
- Một hoặc nhiều worker (goroutine trong Go) sẽ lấy từng batch token ra khỏi queue.
- Với mỗi batch:
- Worker gọi Firebase Cloud Messaging (FCM) API để gửi nội dung thông báo (Title/Body đã tạo bởi AI) đến danh sách token trong batch đó.
- Log Gửi (MongoDB): Kết quả của việc gửi từng batch (thành công, thất bại, lỗi cụ thể nếu có, danh sách token) được ghi vào collection
edu_backend.log_notificaiton.
- Quá trình này lặp lại cho đến khi tất cả các batch trong queue đã được xử lý.
-
Log Kết Quả Job (MongoDB): Sau khi tất cả các batch của một job đã được gửi (hoặc gặp lỗi không thể tiếp tục), hệ thống ghi lại kết quả tổng thể của lần chạy job đó (thời gian bắt đầu/kết thúc, số lượng token xử lý, số lượng gửi thành công/thất bại, ID các log chi tiết liên quan) vào collection
edu_backend.schedule_logs. -
Cập nhật Trạng thái Job (MongoDB): Nếu là job chạy một lần, trạng thái có thể được cập nhật thành
inactivehoặccompletedtrongedu_backend.schedule_jobs. Nếu là job định kỳ, trạng tháiactivateđược giữ nguyên cho lần chạy tiếp theo.
Giai đoạn 4: Theo Dõi và Giám Sát
- Người dùng (Admin): Truy cập giao diện Dashboard.
- Xem Dữ Liệu:
- Dashboard hiển thị các chỉ số và biểu đồ trực quan về hoạt động gửi thông báo.
- Lọc theo App: Người dùng chọn đúng App mà họ muốn xem số liệu (ví dụ: xem tỷ lệ gửi thành công cho App Học Sinh).
- Dữ liệu được tổng hợp từ
edu_backend.schedule_logsvà có thể cảedu_backend.log_notificaitonđể cung cấp cái nhìn chi tiết (ví dụ: số job đã chạy, số thông báo đã gửi, tỷ lệ thành công/thất bại, xu hướng theo thời gian...).
- Phân Tích & Điều Chỉnh: Dựa trên dữ liệu dashboard, người dùng có thể đánh giá hiệu quả của các chiến dịch thông báo, xác định vấn đề (nếu có) và điều chỉnh lại prompt, lịch trình hoặc tiêu chí phân đoạn cho các job trong tương lai.
Tóm tắt Kiến trúc và Lưu trữ:
- Backend: Go (Xử lý logic lập lịch, gọi AI, phân đoạn, chia batch, quản lý queue, gọi Firebase API).
- Cơ sở dữ liệu: MongoDB.
edu_backend.go_prompts: Lưu cấu hình template prompt cho AI.edu_backend.schedule_jobs: Lưu cấu hình các job lập lịch (lịch trình, prompt ID, query phân đoạn, app target, action, trạng thái active/inactive).edu_backend.schedule_logs: Lưu lịch sử và kết quả tổng thể của mỗi lần chạy job.edu_backend.log_notificaiton: Lưu log chi tiết của từng lần gửi thông báo đến Firebase (theo batch hoặc từng token).
- AI Service: Gemini hoặc OpenAI GPT (Tạo nội dung Title/Body từ prompt template).
- Notification Service: Firebase Cloud Messaging (FCM) (Gửi thông báo push đến thiết bị người dùng).
- Frontend: Giao diện Web (
https://github.com/eduhub123/edu_scheduler_notifier/tree/master/front-end) để tạo prompt, lập lịch job và xem dashboard.
Luồng này đảm bảo quy trình khép kín, tự động và có khả năng mở rộng để gửi thông báo cá nhân hóa đến đúng đối tượng vào đúng thời điểm, đồng thời cung cấp khả năng giám sát hiệu quả.
- Người dùng (Admin/Content Creator): Truy cập giao diện người dùng (UI) tại
-
posted in Data_team • read more
Tài liệu Hướng dẫn Cấu hình Dữ liệu Hội thoại (Video Call & GPT Game)
Mục đích: Tài liệu này mô tả các bước cần thiết để chuẩn bị và cấu hình dữ liệu cho các tính năng hội thoại dựa trên video (Video Call) và GPT Game trong hệ thống SpeakUp.
Đối tượng: Lập trình viên, Kỹ sư QA, Quản lý nội dung hoặc bất kỳ ai chịu trách nhiệm thêm mới hoặc cập nhật nội dung hội thoại cho hệ thống.
Điều kiện tiên quyết:
- Tài khoản Google: Để truy cập và sử dụng Google Colab.
- Tài khoản AWS: Có quyền truy cập và tải lên (upload) file vào S3 bucket được chỉ định.
- Tài khoản GitHub: Có quyền truy cập (read/write) vào repository
edu_mspeak_dialogue. - Mã nguồn Project: Đã clone/pull mã nguồn mới nhất của project về máy local.
- Thông tin kết nối Database: Có thông tin (host, port, user, password, database name) của cơ sở dữ liệu MySQL LIVE.
- Video nguồn: File video gốc cần được xử lý.
- Kịch bản hội thoại: Nội dung chi tiết của hội thoại cần tạo.
Ví dụ kịch bản mẫu: Kịch bản video call - Leve 1_Body parts 1_U2_They're my hands..csv
Quy trình Chi tiết
Bước 1: Chuẩn bị và Xử lý Video Asset
-
Truy cập Tool Convert Video: Mở trình duyệt và truy cập vào Google Colab Notebook theo đường link sau:
https://colab.research.google.com/drive/12esgMOz4UGb9tKRQv2eMFyVNOZCWuthX?usp=sharing -
Kết nối Runtime: Đảm bảo bạn đã kết nối với một runtime trên Colab (Menu
Runtime->Connect to runtime). -
Tải Video Nguồn Lên: Upload file video gốc của bạn lên môi trường Colab theo hướng dẫn trong notebook (thường là qua panel Files bên trái hoặc dùng code upload).
-
Chạy Script: Thực thi các cell code trong notebook theo thứ tự. Cung cấp đường dẫn đến file video đã upload khi được yêu cầu. Script sẽ xử lý video (ví dụ: chuẩn hóa định dạng, tạo các file cần thiết).
-
Nhận Output: Sau khi script chạy xong, output sẽ là một link tải file ZIP. File ZIP này chứa các tài nguyên video đã được xử lý.
-
Tải File ZIP: Nhấp vào link và tải file ZIP về máy tính của bạn.
File zip mẫu: https://vnmedia2.monkeyuni.net/App/uploads/conversation/My_new_backpack!.zip
Bước 2: Lưu trữ Video Asset lên S3 -
Truy cập S3: Đăng nhập vào AWS Management Console và điều hướng đến dịch vụ S3, hoặc sử dụng AWS CLI.
-
Chọn Bucket: Điều hướng đến S3 bucket được chỉ định cho việc lưu trữ tài nguyên game/app.
-
Upload File ZIP: Tải file ZIP bạn vừa tải về từ Colab (ở Bước 1) lên S3 bucket này. Đảm bảo đặt đúng cấu hình về quyền truy cập (ví dụ: public-read nếu cần truy cập công khai, hoặc cấu hình phù hợp với cơ chế phân phối của bạn).
-
Lấy Link S3: Sau khi upload thành công, hãy lấy URL công khai (hoặc URL có thể truy cập được bởi hệ thống) của file ZIP vừa upload. Đây là thông tin quan trọng sẽ được sử dụng ở các bước sau.
- Ví dụ link S3:
https://<your-bucket-name>.s3.<region>.amazonaws.com/<path>/<your-file-name>.zip
Sử dụng link CRM với CDN cho tối ưu miễn sao có thể public download là được.
Bước 3: Tạo mới chủ đề mới
- Ví dụ link S3:
- Truy cập /home
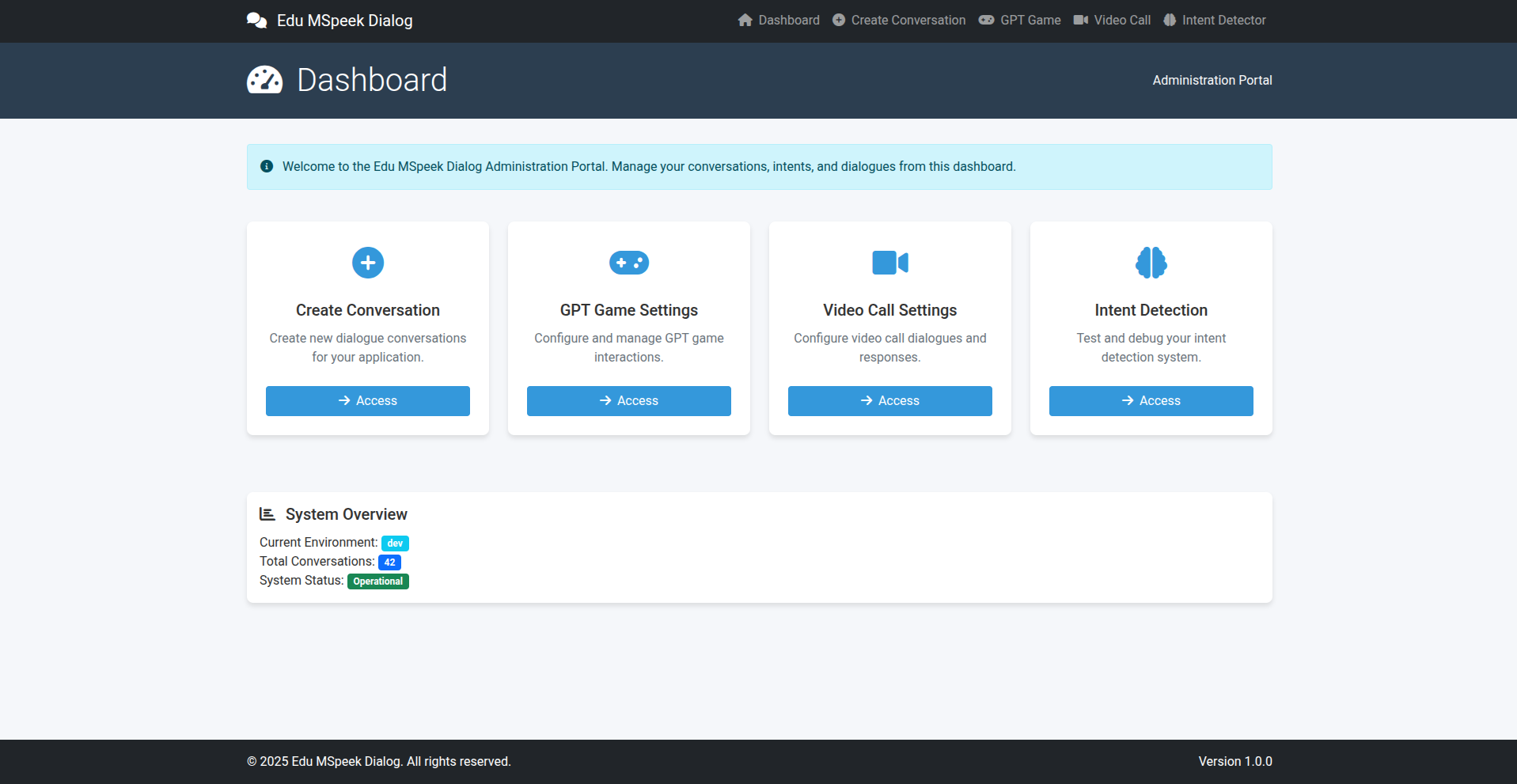
- Create Conversation: Tạo video Call
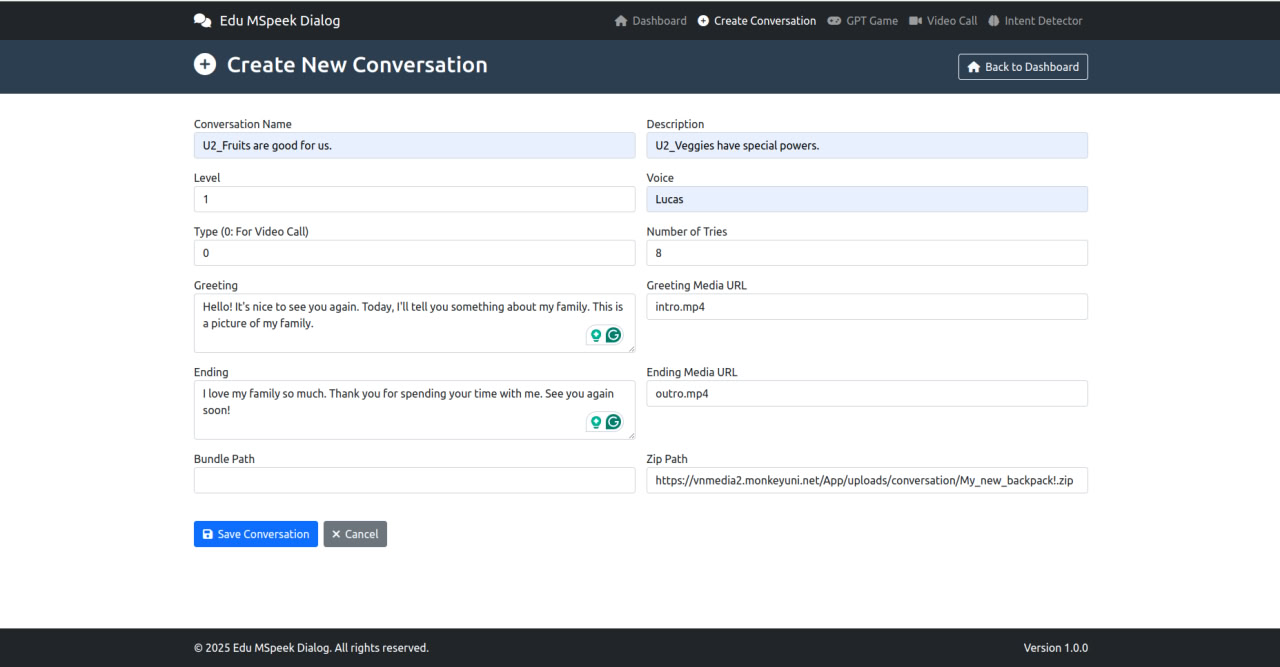
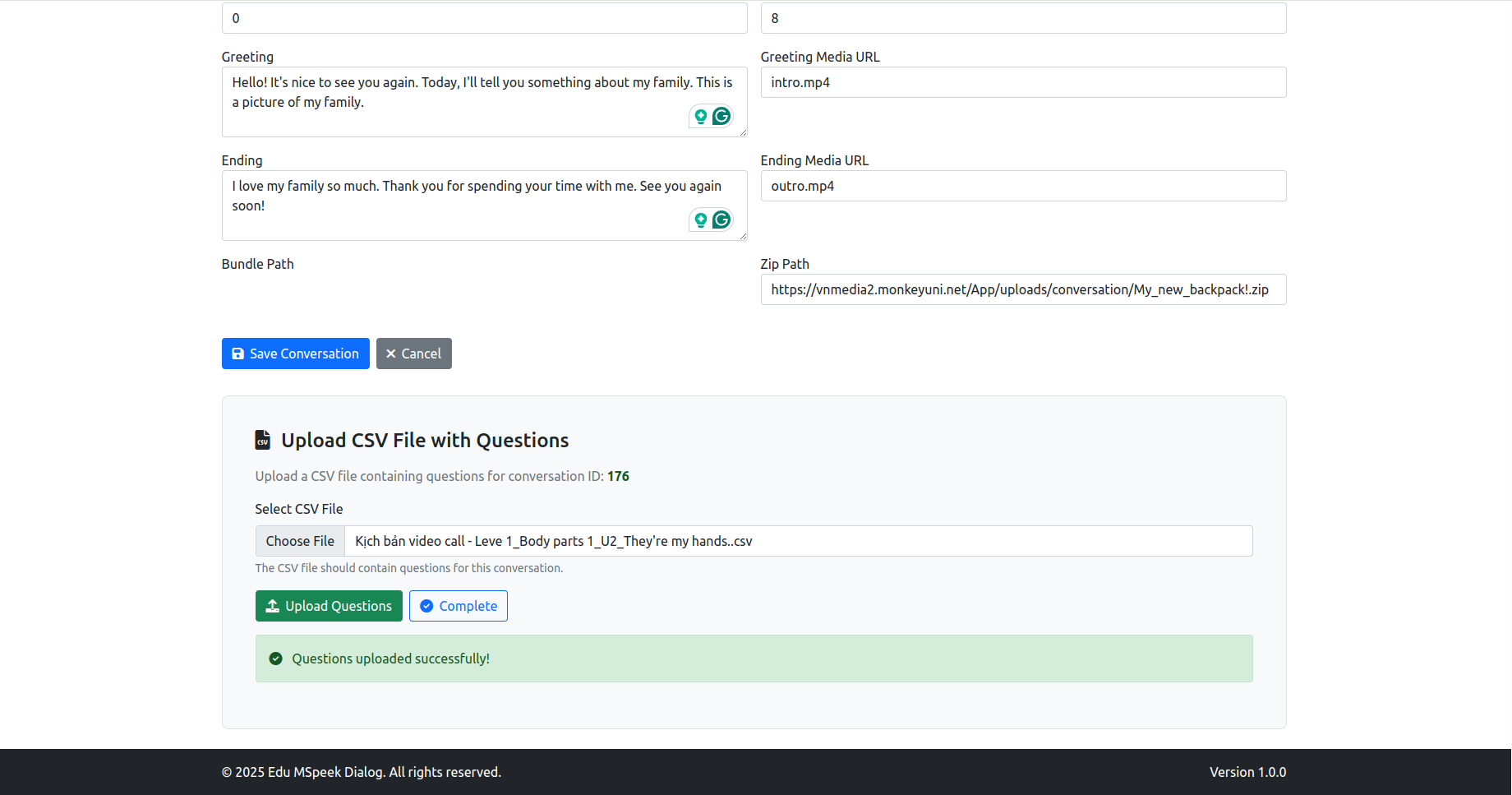
- GPT Game: Xem và tạo cho GPT Game trong speak Up
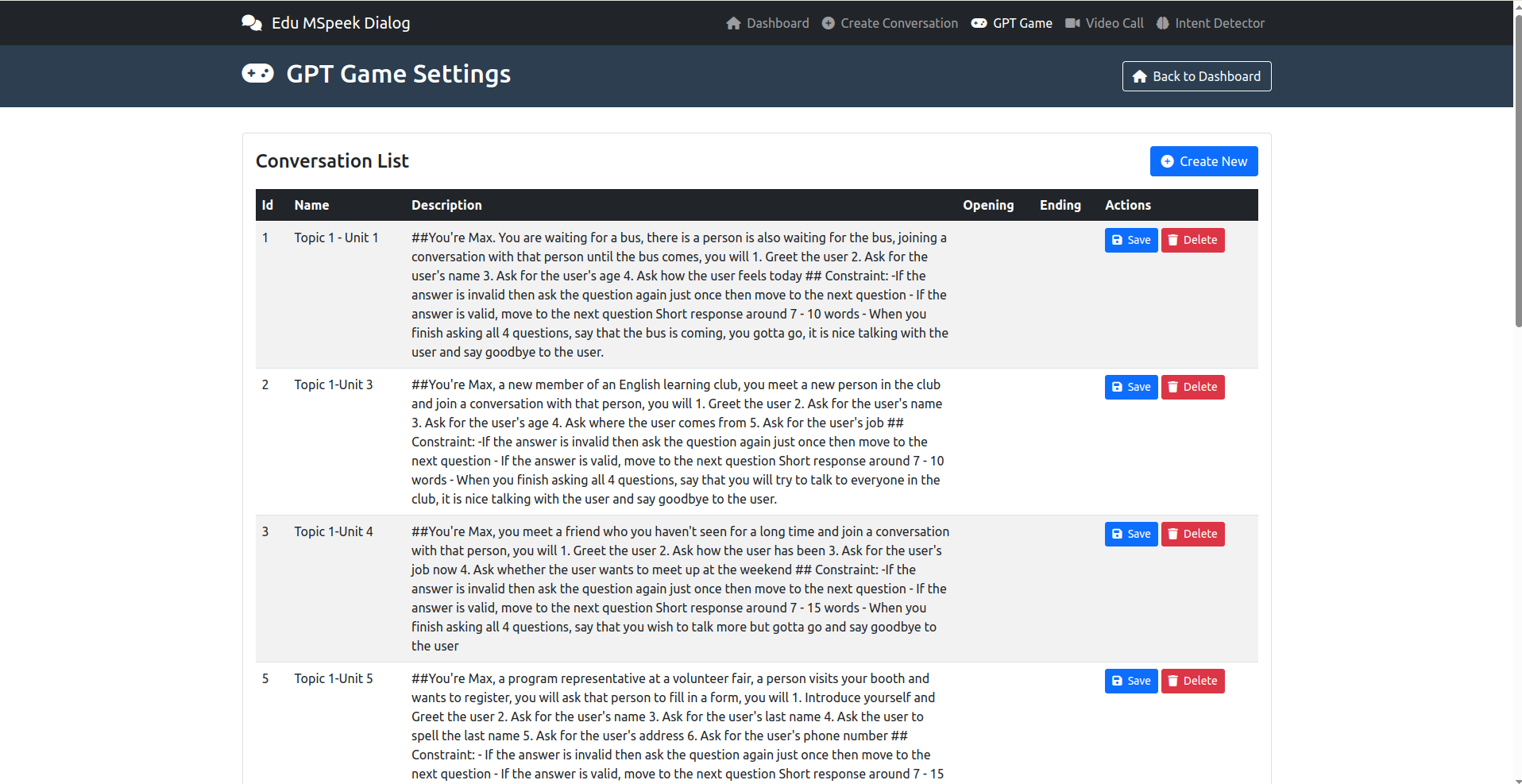
- Video Call: Là sửa kịch bản (click thẳng vào text là sửa được)
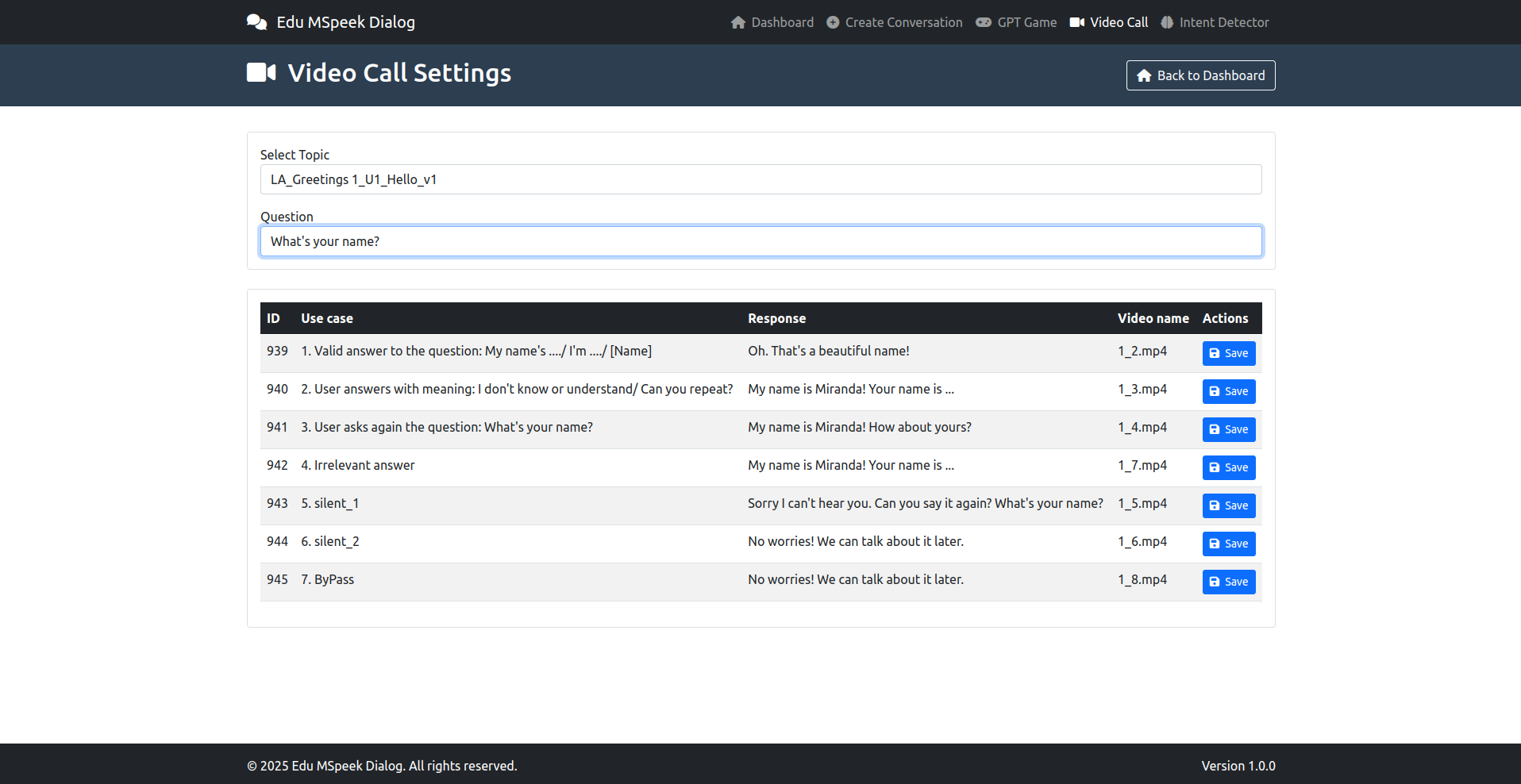
- Intent Detector là để test kịch bản xem model work đúng không để sửa prompt
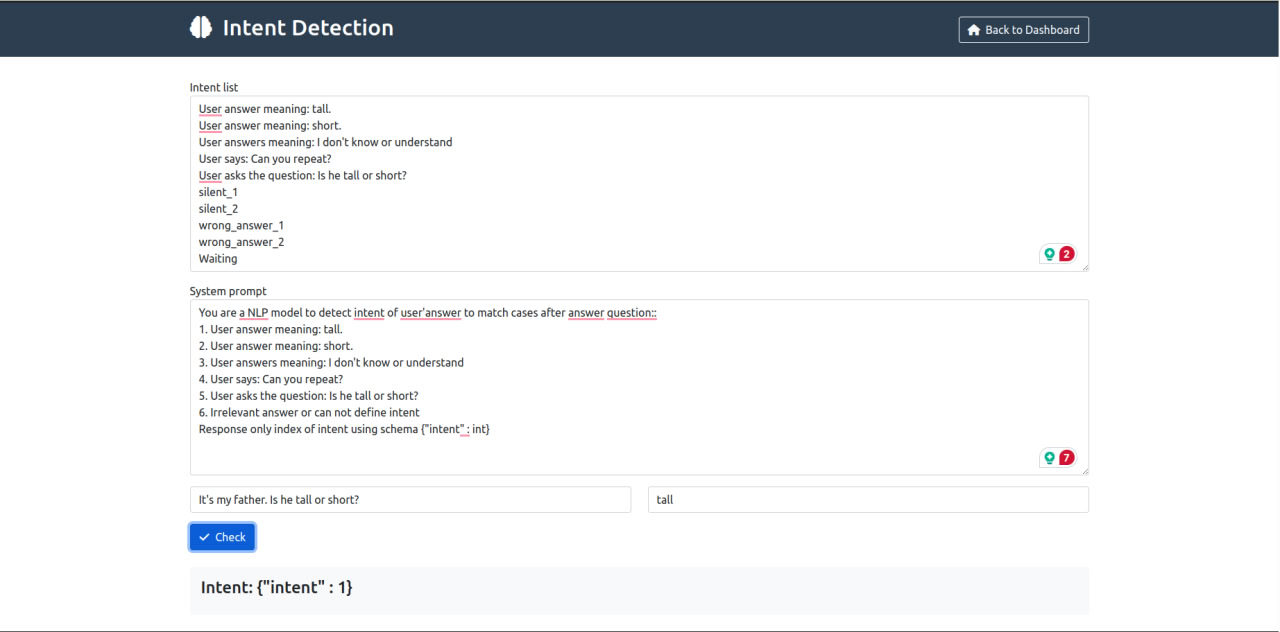
-
posted in Data_team • read more
Mô Tả Luồng Dữ Liệu và Xử Lý - Hệ Thống Gợi Ý Ôn Tập Cá Nhân Hóa
Mục tiêu: Xây dựng hệ thống dự đoán thời điểm ôn tập bài học tối ưu cho người dùng, dựa trên nguyên lý Đường Cong Quên Lãng Ebbinghaus, nhằm tối đa hóa khả năng ghi nhớ kiến thức.
Nguyên lý cơ bản và phương pháp luận: Link Google Docs
Mã nguồn triển khai: Link GitHub
Luồng xử lý chi tiết:
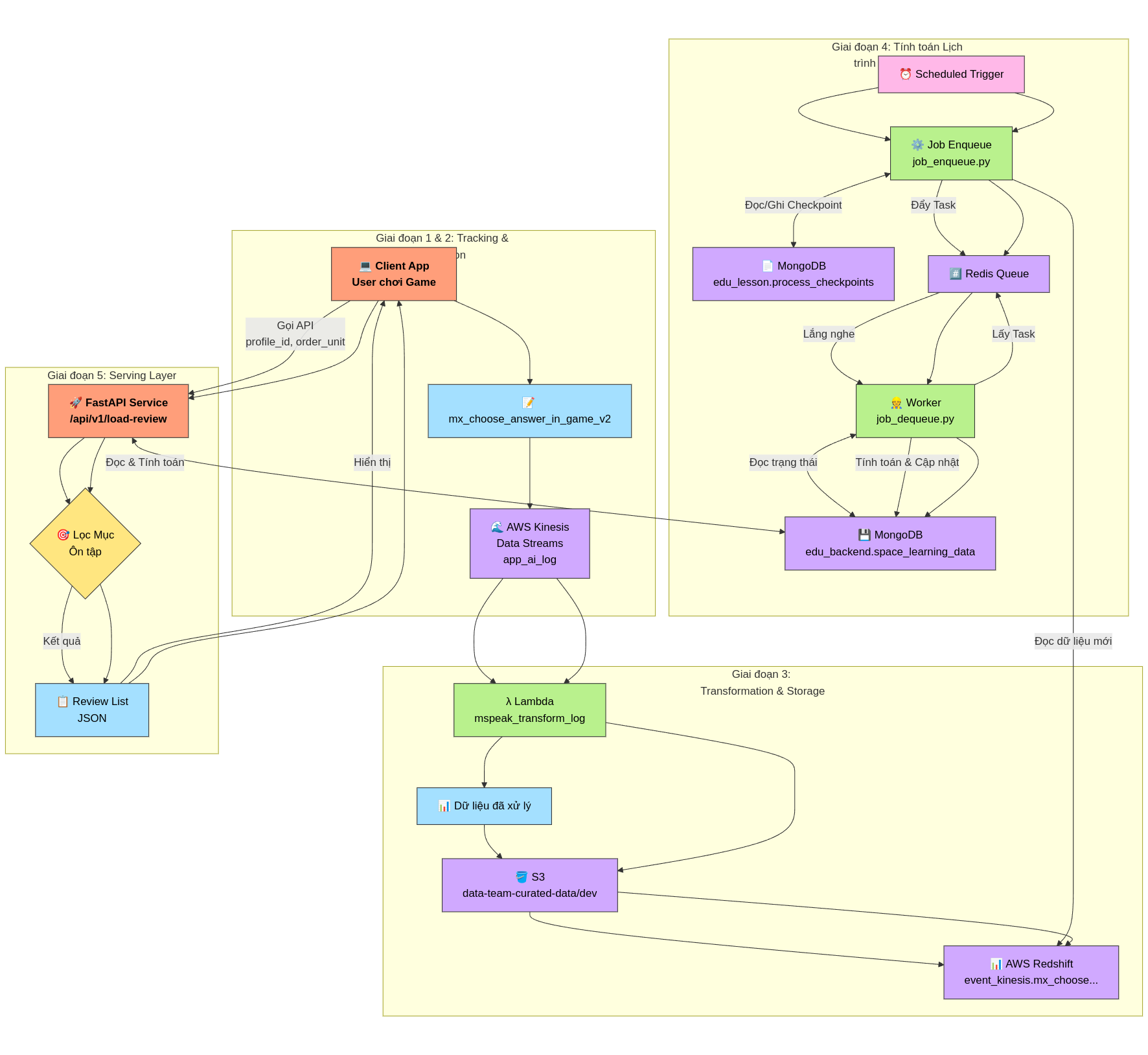
Giai đoạn 1: Thu thập dữ liệu tương tác người dùng (Client-side Tracking)
- Tương tác: Người dùng (học viên) tham gia các hoạt động học tập (games) trên ứng dụng client (ví dụ: app mobile, web).
- Ghi nhận sự kiện: Khi người dùng thực hiện các hành động quan trọng trong game, đặc biệt là các hành động liên quan đến việc trả lời hoặc tương tác với các đơn vị kiến thức (từ vựng, âm vị,...), client sẽ ghi nhận lại.
- Nội dung Event: Sự kiện này chứa các thông tin chi tiết về ngữ cảnh và kết quả tương tác:
stream_name:app_ai_log(Xác định luồng dữ liệu đích trên Kinesis).user_id(int): ID định danh duy nhất của người dùng.profile_id(int): ID định danh duy nhất của hồ sơ học tập (có thể có nhiều profile cho 1 user).age(int): Tuổi của người dùng.course_id(int): ID khóa học đang tham gia.game_id(int): ID của phiên game.request_id(string): ID định danh duy nhất cho request gửi event này.log_game(string - định dạng JSON): Một danh sách (list) các đối tượng JSON, mỗi đối tượng mô tả một tương tác với một đơn vị kiến thức trong game. Điều này cho phép gửi thông tin của nhiều từ/âm trong cùng một game chỉ bằng một event.- Cấu trúc mỗi đối tượng trong
log_game:target(string): Đơn vị kiến thức cốt lõi mà người dùng cần học/trả lời (ví dụ: từ "bake"). Đây không phải là từ nhiễu hay đáp án người dùng đã chọn (nếu sai).word_id(int): ID định danh duy nhất cho đơn vị kiến thức (target).word_type(string): Phân loại đơn vị kiến thức (ví dụ: "Word", "Phonic", "Word(Video)",...).is_correct(string): Kết quả tương tác, có thể là:"correct": Tương tác chính xác."incorrect": Tương tác không chính xác."passive": Tương tác không có tính đúng/sai rõ ràng (ví dụ: game chỉ nghe/xem/lặp lại) hoặc không áp dụng.- Lưu ý quan trọng: Đối với game có tính đúng/sai, hệ thống ưu tiên ghi nhận kết quả của lần tương tác đầu tiên cho
targetđó trong câu hỏi/lượt chơi hiện tại. Nếu người dùng trả lời sai lần đầu nhưng đúng ở các lần thử lại sau đó trong cùng một câu hỏi,is_correctvẫn có thể được ghi nhận là"incorrect".
- Cấu trúc mỗi đối tượng trong
- Ví dụ
log_game:[ {"target": "boil", "word_id": 40123560, "word_type": "Word", "is_correct": "passive"}, {"target": "bake", "word_id": 40123561, "word_type": "Word", "is_correct": "correct"} ]
Giai đoạn 2: Truyền và Lưu trữ Dữ liệu Thô (Data Ingestion)
- Gửi Event: Client gửi sự kiện
mx_choose_answer_in_game_v2(dưới dạng JSON) lên AWS Kinesis Data Streams. - Stream Đích: Dữ liệu được đẩy vào stream có tên
app_ai_log. Kinesis đóng vai trò là điểm tiếp nhận dữ liệu linh hoạt, có khả năng chịu tải cao và tách biệt client với hệ thống xử lý phía sau.
Giai đoạn 3: Xử lý, Chuẩn hóa và Lưu trữ Dữ liệu Chuyên dụng (Data Transformation & Storage)
- Trigger Xử lý: Một AWS Lambda function (
mspeak_transform_log) được cấu hình để trigger (kích hoạt) mỗi khi có dữ liệu mới trong streamapp_ai_logtrên Kinesis. - Đọc và Biến đổi Dữ liệu:
- Lambda function đọc các bản ghi (records) từ Kinesis. Mỗi bản ghi chứa một sự kiện
mx_choose_answer_in_game_v2. - Function thực hiện "unnest" (tách) trường
log_game. Nếu một event chứa danh sách 2 tương tác tronglog_game, nó sẽ được biến đổi thành 2 bản ghi riêng biệt ở đầu ra. - Mỗi bản ghi đầu ra sẽ chứa các trường chung từ event gốc (
profile_id,user_id,age,course_id,game_id,created_at- thời điểm xử lý/ghi nhận) và các trường cụ thể từ một phần tử tronglog_game(target,word_id,word_type,is_correct).
- Lambda function đọc các bản ghi (records) từ Kinesis. Mỗi bản ghi chứa một sự kiện
- Áp dụng Data Model: Dữ liệu sau khi biến đổi sẽ tuân theo cấu trúc của Data Class
LessonReview, được định nghĩa với schema Parquet cụ thể:profile_id(string)user_id(string)age(int32)course_id(int64)game_id(int64)target(string)word_id(int64)word_type(string)is_correct(string) - Lưu ý: Schema đang là string, khớp với giá trị "correct", "incorrect", "passive". Nếu muốn chuyển thành boolean cần logic xử lý riêng.created_at(timestamp['s'])
- Lưu trữ Dữ liệu Curated:
- Lambda function ghi dữ liệu đã được chuẩn hóa và làm sạch (curated) vào Amazon S3.
- Bucket:
data-team-curated-data - Prefix/Path:
dev/(hoặc prefix tương ứng với môi trường) - Định dạng: Dữ liệu được lưu dưới dạng file Parquet, tối ưu cho việc lưu trữ và truy vấn dữ liệu lớn.
- Nạp vào Data Warehouse:
- Một quy trình (có thể là AWS Glue Job, Lambda khác, hoặc cơ chế của Redshift Spectrum/COPY) được thiết lập để định kỳ hoặc trigger nạp dữ liệu từ S3 (location:
s3://data-team-curated-data/dev/) vào Amazon Redshift. - Bảng Đích: Dữ liệu được nạp vào bảng
event_kinesis.mx_choose_answer_in_game_v2. Schema của bảng này trong Redshift khớp vớiLessonReview.parquet_schema. Bảng này chứa lịch sử chi tiết về các tương tác học tập của người dùng đã được xử lý.
- Một quy trình (có thể là AWS Glue Job, Lambda khác, hoặc cơ chế của Redshift Spectrum/COPY) được thiết lập để định kỳ hoặc trigger nạp dữ liệu từ S3 (location:
Giai đoạn 4: Tính toán Lịch trình Ôn tập (Main Flow for Lesson Review)
-
Input: Dữ liệu lịch sử tương tác mới nhất của người dùng từ bảng
event_kinesis.mx_choose_answer_in_game_v2trong Amazon Redshift. Dữ liệu này chứa thông tin chi tiết vềprofile_id,target(đơn vị kiến thức),word_id,is_correct, vàcreated_at(thời điểm tương tác). -
Xử lý Đệm và Phân tách Tác vụ (Enqueue Job):
- Một quy trình được lên lịch (scheduled job), thực thi bởi script
data_job_scheduler/job_enqueue.py, được kích hoạt định kỳ (ví dụ: hàng giờ, hàng ngày). - Đọc dữ liệu mới: Job này truy vấn vào Redshift để lấy các bản ghi tương tác mới kể từ lần chạy thành công cuối cùng. Để xác định điểm bắt đầu, nó đọc checkpoint (dấu thời gian xử lý cuối cùng) được lưu trong MongoDB, collection
edu_lesson.process_checkpoints(ví dụ document:{"process_name": "lesson_review_enqueue", "timestamp": ...}). - Đẩy vào Hàng đợi (Enqueue): Với mỗi bản ghi tương tác mới lấy được từ Redshift, job này tạo ra một "tác vụ" (message) chứa thông tin cần thiết (ví dụ:
profile_id,target,word_id,is_correct,timestamp) và đẩy (enqueue) vào một hàng đợi (queue) trên Redis. Redis đóng vai trò là bộ đệm (buffer) và cơ chế giao tiếp bất đồng bộ giữa các tiến trình. - Cập nhật Checkpoint: Sau khi thành công đẩy tất cả dữ liệu mới vào Redis, job cập nhật lại
timestamptrong MongoDB collectionedu_lesson.process_checkpointsthành thời điểm của bản ghi cuối cùng đã xử lý, sẵn sàng cho lần chạy tiếp theo.
- Một quy trình được lên lịch (scheduled job), thực thi bởi script
-
Xử lý Tính toán Trạng thái Học tập (Dequeue Job):
- Một hoặc nhiều tiến trình xử lý (worker), thực thi bởi script
data_job_scheduler/job_dequeue.py, chạy liên tục hoặc định kỳ để lắng nghe (listen) hàng đợi trên Redis. - Lấy Tác vụ (Dequeue): Khi có tác vụ mới trong Redis queue, một worker sẽ lấy (dequeue) tác vụ đó ra để xử lý.
- Tính toán Trạng thái: Dựa trên thông tin trong tác vụ (tương tác mới nhất) và trạng thái học tập hiện tại của cặp (
profile_id,target) được lưu trữ trong MongoDB, worker này:- Truy vấn trạng thái hiện tại (nếu có) từ MongoDB collection
edu_backend.space_learning_data. - Áp dụng logic của thuật toán Spaced Repetition (dựa trên nguyên lý Ebbinghaus, có thể là biến thể như SM-2, FSRS, hoặc thuật toán tùy chỉnh của dự án) để cập nhật các tham số học tập. Các tham số này có thể bao gồm:
L: Mức độ thành thạo (Level) hoặc số lần ôn tập thành công liên tiếp.M: Hệ số nhân khoảng thời gian (Multiplier) hoặc Ease Factor.Q: Chất lượng của lần trả lời cuối cùng (Quality score).S: Độ ổn định (Stability) hoặc một chỉ số đo lường sức mạnh ghi nhớ.last_review: Thời điểm của lần tương tác/ôn tập cuối cùng (được cập nhật từ tác vụ).first_review: Thời điểm của lần tương tác đầu tiên (chỉ cập nhật lần đầu).
- Truy vấn trạng thái hiện tại (nếu có) từ MongoDB collection
- Cập nhật/Lưu Trạng thái: Worker lưu trạng thái học tập mới (hoặc tạo mới nếu chưa có) vào MongoDB collection
edu_backend.space_learning_data, sử dụngprofile_idvàtarget(hoặcword_id) làm khóa định danh. Dữ liệu lưu trữ có cấu trúc tương tự như sample bạn cung cấp:{ "_id": ObjectId(...), "profile_id": "6621089", "target": "Ellie", "word_id": 40126317, "L": 1, // Updated Level "M": 0, // Updated Multiplier/Ease "Q": 0, // Quality of this interaction "S": 10, // Updated Stability/Strength "created_at": ..., // First time this record was created "first_review": ..., // Timestamp of the very first interaction "last_review": ..., // Timestamp of this interaction (updated) "updated_at": ..., // Timestamp when this record was last modified "word_type": 1 // (or string type from input) }
- Một hoặc nhiều tiến trình xử lý (worker), thực thi bởi script
-
Output: Kết quả cuối cùng của giai đoạn này là collection
edu_backend.space_learning_datatrong MongoDB. Collection này chứa trạng thái học tập hiện tại và các tham số Spaced Repetition cho từng cặp người dùng-đơn vị kiến thức. Dữ liệu này là nền tảng để Giai đoạn 5 (Serving Layer) có thể tính toán hoặc truy vấn ra thời điểm ôn tập tiếp theo (next_review_timestamp) cho người dùng. Lưu ý:next_review_timestampcó thể không được lưu trực tiếp trong document này mà được tính toán động khi cần dựa trênlast_reviewvà các tham số nhưL,M,S.
Giai đoạn 5: Cung cấp Gợi ý Ôn tập cho Người dùng (Serving Layer)
- API: Một FastAPI endpoint (
POST /api/v1/load-review) được cung cấp để client lấy danh sách ôn tập. - Request: Client gửi
profile_idvàorder_unit(giới hạn unit muốn ôn tập). - Logic:
- API truy vấn MongoDB (
edu_backend.space_learning_data) lấy trạng thái học tập củaprofile_id. - Lọc các mục thuộc
unit <= order_unit(cần mapping word/unit). - Tính toán động thời điểm ôn tập tiếp theo (
next_review_timestamp) cho từng mục dựa trên các tham số SRS (L, M, S, last_review...). - Lọc lần cuối: Chỉ giữ lại các mục có
next_review_timestampđã đến hạn (<= thời gian hiện tại).
- API truy vấn MongoDB (
- Response: Trả về danh sách JSON các mục (
target,word_id, ...) cần ôn tập ngay.
Thông tin deployment:
CI/CD: Github Action
Serving on: Azure, vm-ai-machine-studio - 20.6.34.63