Triton Serving for AI Model
In this repo at the branch "triton_serving", we will provide sources and guides for production model AI through TensorRt and Triton Serving.
Install requirements
Triton supports some platforms to bring your AI model to production with high performance, such as Torch, TensorFlow, TensorRT, Onnx, and Pure Python.
In some cases, if you want to run your code with pure Python, some third-party libraries are required. You should create a custom base image.
Creating a base image
I attached a Dockerfile to build a custom base image with requirements.txt.
To build a base image, please insert your libraries into requirements.txt. Don't forget to define the version.
docker build. -t <image_name>:<image_tag>
Note: You can change the image name and image tag in <image_name>:<image_tag>.
Converting model
You can use any framework to develop your model, such as TensorFlow, Python, etc. But the pure framework is quite slow in production. So I strongly recommend converting to another format, such as ONNX or TensorRT.
You can use any framework to develop your model, such as TensorFlow, Python, etc. But the pure framework is quite slow in production. So I strongly recommend converting to another format, such as ONNX or TensorRT.
While converting, you can set fp16 mode or int8 to speed up inference time. But let's remember that you need to check again about the precision of the model after it was converted.
Two common cases:
-
ONNX with fp16 or fp32
-
TensorRT: fp16, fp32 or int8
1. Installation
If you want to install the TensorRT environment on your local machine, you can follow the instructions or documents
You can face some issues when installing on a local machine. You can check again about the version.
Another way is that it is easy to use and rapid to set up. Docker is a wonderful solution to address any problems related to installation.
docker run -d --gpus all -it --rm -v ./:/workspace nvcr.io/nvidia/tensorrt:23.09-py3
To finish setting up Triton with Docker, follow the command below. It would be best if you mapped your workspace in the host machine into Docker workspace by argument -v.
The NVIDIA team was exposed to a stage for converting the model from deep learning frameworks to inference frameworks.
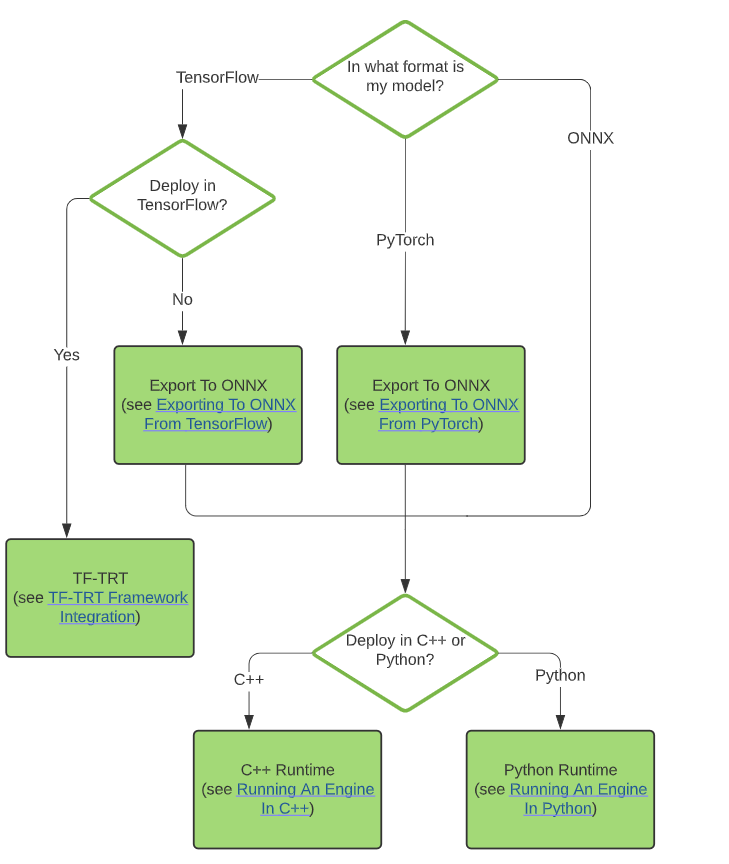
2. Converting to ONNX
The entire model should be converted to ONNX before being transferred to TensorRT. You can follow 2 instructions below to convert your model.
The Monkey's ONNX model was saved at S3: data-team-media-ai/model-zoo/onnx_model_zoo/
2. Converting to TensorRT
I used Docker to convert my model to TensorRT, you can refer my command below:
trtexec --onnx=models/openai/whisper-small/onnx/whisper-small-encoder.onnx --saveEngine='model.engine' --explicitBatch --workspace=1024
-
ONNX: path of the model ONNX
-
saveEngine: path of TensorRT model
-
explicitBatch: This option will allow for a fixed batch size.
-
workspace: the value allows to set maximum memory for each layer in the model
If you want to run fp16, or int8 add an argument into the command as:
trtexec --onnx=onnx/question_statement/torch-model.onnx --saveEngine='model.engine' --explicitBatch --workspace=1024 --fp16
If you want to set a dynamic axis for the TensorRT model:
trtexec --onnx=onnx/sentence_transformer/all-mpnet-base-v2.onnx --saveEngine='model.engine' --minShapes=input_ids:1x1,attention_mask:1x1 --optShapes=input_ids:1x15,attention_mask:1x15 --maxShapes=input_ids:1x384,attention_mask:1x384
We can export any name you want, but to identify the model, it is a TensorRT model or not? We should set the file extension to one in three [.plan, .trt, .engine]. But Triton only can see .plan file.
Serving Triton
After converting the model to TensorRT format, We can bring them to our production through Triton Serving.
Some steps to apply them to products:
- Create a model_repository
This folder will be used to covert entire your model.
model_repository
|
+-- handwriting
|
+-- config.pbtxt
+-- 1
|
+-- model.onnx
- Define the model config inside config.pbtxt:
name: "handwriting"
platform: "onnxruntime_onnx"
max_batch_size : 32
input [
{
name: "input_1"
data_type: TYPE_FP32
format: FORMAT_NHWC
dims: [ 128, 128, 3 ]
reshape { shape: [128, 128, 3 ] }
}
]
output [
{
name: "dense_1"
data_type: TYPE_FP32
dims: [ 26 ]
reshape { shape: [ 26] }
label_filename: "labels.txt"
}
]
name: model name, it is the name of the folder too.
platform: env to run your model [onnxruntime_onnx, tensorrt_plan, torch, ...]
max_batch_size: the maximum batch size of the model
input: define the input of API
output: define the structure of the response
In a model_repository, you can define many sub-folders; it is equivalent to a model.
After converting the model, don't forget to upload it to S3:
aws s3 sync model_repository s3://data-team-media-ai/model-zoo/triton/
- Serving
docker run -d --gpus all --rm --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 -v/home/mautrung/edu_ai_triton_serving/model_repository:/models nvcr.io/nvidia/tritonserver:23.09-py3-custom tritonserver --model-repository=/models
Note: Some requirements about the device to run Triton
- A Nvidia GPU was installed.
- Docker and Docker-compose
- [Nvidia Container Toolkit] (https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)
Testing
Triton provides both protocols: GRPC (8001) and HTTP (8000).
Benchmark API from Triton
We can benchmark the model, that was started up by Triton by Apache Benchmark tool.
ab -p data_samples/body_bm_wav2vec/bm_w2v.txt -T application/json -c 100 -n 1000 http://localhost:8000/v2/models/wav2vec_trt/infer
- data_samples/body_bm_wav2vec/bm_w2v.txt: The file contains the body of the request. It has JSON format but it is saved into a .txt file.
- -c: concurrency requests.
- -n: number of requests will be used.
Some sample data in a folder: data_samples
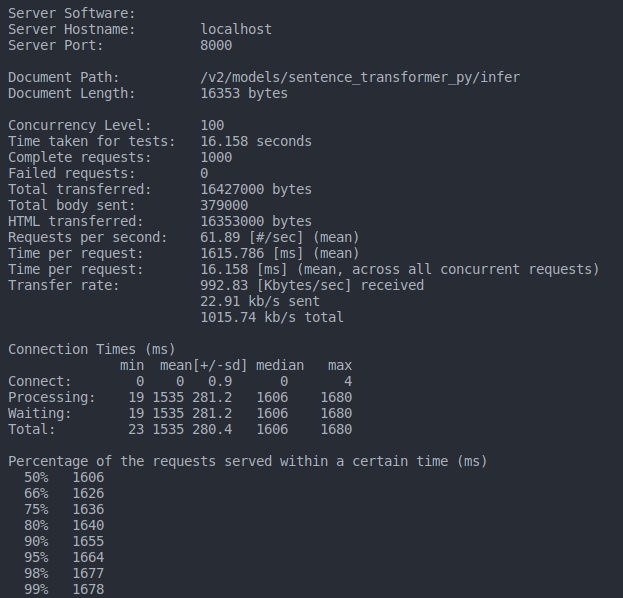
Result: