Mô Tả Luồng Dữ Liệu và Xử Lý - Hệ Thống Gợi Ý Ôn Tập Cá Nhân Hóa
Mục tiêu: Xây dựng hệ thống dự đoán thời điểm ôn tập bài học tối ưu cho người dùng, dựa trên nguyên lý Đường Cong Quên Lãng Ebbinghaus, nhằm tối đa hóa khả năng ghi nhớ kiến thức.
Nguyên lý cơ bản và phương pháp luận: Link Google Docs
Mã nguồn triển khai: Link GitHub
Luồng xử lý chi tiết:
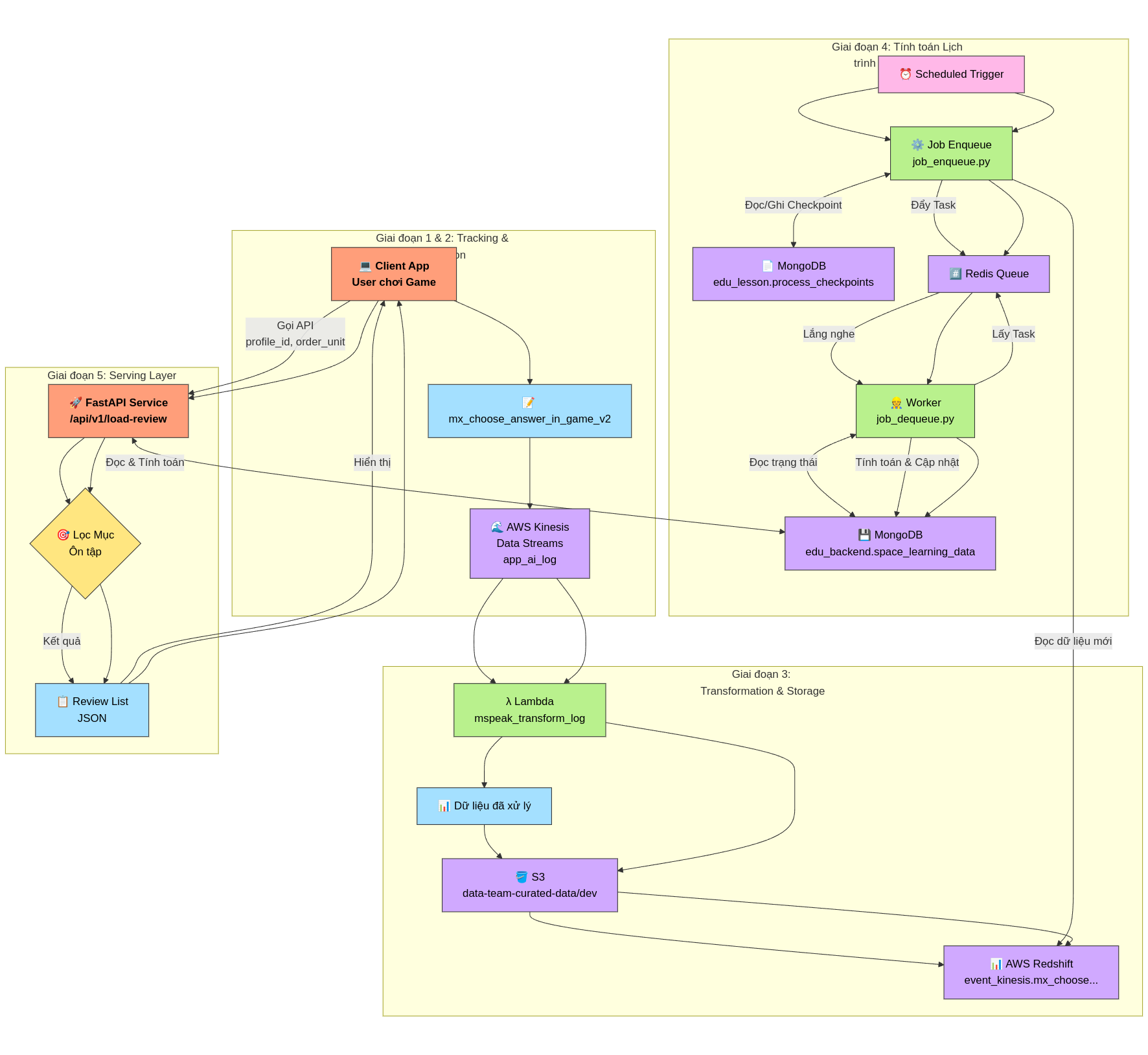
Giai đoạn 1: Thu thập dữ liệu tương tác người dùng (Client-side Tracking)
- Tương tác: Người dùng (học viên) tham gia các hoạt động học tập (games) trên ứng dụng client (ví dụ: app mobile, web).
- Ghi nhận sự kiện: Khi người dùng thực hiện các hành động quan trọng trong game, đặc biệt là các hành động liên quan đến việc trả lời hoặc tương tác với các đơn vị kiến thức (từ vựng, âm vị,...), client sẽ ghi nhận lại.
- Nội dung Event: Sự kiện này chứa các thông tin chi tiết về ngữ cảnh và kết quả tương tác:
stream_name:app_ai_log(Xác định luồng dữ liệu đích trên Kinesis).user_id(int): ID định danh duy nhất của người dùng.profile_id(int): ID định danh duy nhất của hồ sơ học tập (có thể có nhiều profile cho 1 user).age(int): Tuổi của người dùng.course_id(int): ID khóa học đang tham gia.game_id(int): ID của phiên game.request_id(string): ID định danh duy nhất cho request gửi event này.log_game(string - định dạng JSON): Một danh sách (list) các đối tượng JSON, mỗi đối tượng mô tả một tương tác với một đơn vị kiến thức trong game. Điều này cho phép gửi thông tin của nhiều từ/âm trong cùng một game chỉ bằng một event.- Cấu trúc mỗi đối tượng trong
log_game:target(string): Đơn vị kiến thức cốt lõi mà người dùng cần học/trả lời (ví dụ: từ "bake"). Đây không phải là từ nhiễu hay đáp án người dùng đã chọn (nếu sai).word_id(int): ID định danh duy nhất cho đơn vị kiến thức (target).word_type(string): Phân loại đơn vị kiến thức (ví dụ: "Word", "Phonic", "Word(Video)",...).is_correct(string): Kết quả tương tác, có thể là:"correct": Tương tác chính xác."incorrect": Tương tác không chính xác."passive": Tương tác không có tính đúng/sai rõ ràng (ví dụ: game chỉ nghe/xem/lặp lại) hoặc không áp dụng.- Lưu ý quan trọng: Đối với game có tính đúng/sai, hệ thống ưu tiên ghi nhận kết quả của lần tương tác đầu tiên cho
targetđó trong câu hỏi/lượt chơi hiện tại. Nếu người dùng trả lời sai lần đầu nhưng đúng ở các lần thử lại sau đó trong cùng một câu hỏi,is_correctvẫn có thể được ghi nhận là"incorrect".
- Cấu trúc mỗi đối tượng trong
- Ví dụ
log_game:[ {"target": "boil", "word_id": 40123560, "word_type": "Word", "is_correct": "passive"}, {"target": "bake", "word_id": 40123561, "word_type": "Word", "is_correct": "correct"} ]
Giai đoạn 2: Truyền và Lưu trữ Dữ liệu Thô (Data Ingestion)
- Gửi Event: Client gửi sự kiện
mx_choose_answer_in_game_v2(dưới dạng JSON) lên AWS Kinesis Data Streams. - Stream Đích: Dữ liệu được đẩy vào stream có tên
app_ai_log. Kinesis đóng vai trò là điểm tiếp nhận dữ liệu linh hoạt, có khả năng chịu tải cao và tách biệt client với hệ thống xử lý phía sau.
Giai đoạn 3: Xử lý, Chuẩn hóa và Lưu trữ Dữ liệu Chuyên dụng (Data Transformation & Storage)
- Trigger Xử lý: Một AWS Lambda function (
mspeak_transform_log) được cấu hình để trigger (kích hoạt) mỗi khi có dữ liệu mới trong streamapp_ai_logtrên Kinesis. - Đọc và Biến đổi Dữ liệu:
- Lambda function đọc các bản ghi (records) từ Kinesis. Mỗi bản ghi chứa một sự kiện
mx_choose_answer_in_game_v2. - Function thực hiện "unnest" (tách) trường
log_game. Nếu một event chứa danh sách 2 tương tác tronglog_game, nó sẽ được biến đổi thành 2 bản ghi riêng biệt ở đầu ra. - Mỗi bản ghi đầu ra sẽ chứa các trường chung từ event gốc (
profile_id,user_id,age,course_id,game_id,created_at- thời điểm xử lý/ghi nhận) và các trường cụ thể từ một phần tử tronglog_game(target,word_id,word_type,is_correct).
- Lambda function đọc các bản ghi (records) từ Kinesis. Mỗi bản ghi chứa một sự kiện
- Áp dụng Data Model: Dữ liệu sau khi biến đổi sẽ tuân theo cấu trúc của Data Class
LessonReview, được định nghĩa với schema Parquet cụ thể:profile_id(string)user_id(string)age(int32)course_id(int64)game_id(int64)target(string)word_id(int64)word_type(string)is_correct(string) - Lưu ý: Schema đang là string, khớp với giá trị "correct", "incorrect", "passive". Nếu muốn chuyển thành boolean cần logic xử lý riêng.created_at(timestamp['s'])
- Lưu trữ Dữ liệu Curated:
- Lambda function ghi dữ liệu đã được chuẩn hóa và làm sạch (curated) vào Amazon S3.
- Bucket:
data-team-curated-data - Prefix/Path:
dev/(hoặc prefix tương ứng với môi trường) - Định dạng: Dữ liệu được lưu dưới dạng file Parquet, tối ưu cho việc lưu trữ và truy vấn dữ liệu lớn.
- Nạp vào Data Warehouse:
- Một quy trình (có thể là AWS Glue Job, Lambda khác, hoặc cơ chế của Redshift Spectrum/COPY) được thiết lập để định kỳ hoặc trigger nạp dữ liệu từ S3 (location:
s3://data-team-curated-data/dev/) vào Amazon Redshift. - Bảng Đích: Dữ liệu được nạp vào bảng
event_kinesis.mx_choose_answer_in_game_v2. Schema của bảng này trong Redshift khớp vớiLessonReview.parquet_schema. Bảng này chứa lịch sử chi tiết về các tương tác học tập của người dùng đã được xử lý.
- Một quy trình (có thể là AWS Glue Job, Lambda khác, hoặc cơ chế của Redshift Spectrum/COPY) được thiết lập để định kỳ hoặc trigger nạp dữ liệu từ S3 (location:
Giai đoạn 4: Tính toán Lịch trình Ôn tập (Main Flow for Lesson Review)
-
Input: Dữ liệu lịch sử tương tác mới nhất của người dùng từ bảng
event_kinesis.mx_choose_answer_in_game_v2trong Amazon Redshift. Dữ liệu này chứa thông tin chi tiết vềprofile_id,target(đơn vị kiến thức),word_id,is_correct, vàcreated_at(thời điểm tương tác). -
Xử lý Đệm và Phân tách Tác vụ (Enqueue Job):
- Một quy trình được lên lịch (scheduled job), thực thi bởi script
data_job_scheduler/job_enqueue.py, được kích hoạt định kỳ (ví dụ: hàng giờ, hàng ngày). - Đọc dữ liệu mới: Job này truy vấn vào Redshift để lấy các bản ghi tương tác mới kể từ lần chạy thành công cuối cùng. Để xác định điểm bắt đầu, nó đọc checkpoint (dấu thời gian xử lý cuối cùng) được lưu trong MongoDB, collection
edu_lesson.process_checkpoints(ví dụ document:{"process_name": "lesson_review_enqueue", "timestamp": ...}). - Đẩy vào Hàng đợi (Enqueue): Với mỗi bản ghi tương tác mới lấy được từ Redshift, job này tạo ra một "tác vụ" (message) chứa thông tin cần thiết (ví dụ:
profile_id,target,word_id,is_correct,timestamp) và đẩy (enqueue) vào một hàng đợi (queue) trên Redis. Redis đóng vai trò là bộ đệm (buffer) và cơ chế giao tiếp bất đồng bộ giữa các tiến trình. - Cập nhật Checkpoint: Sau khi thành công đẩy tất cả dữ liệu mới vào Redis, job cập nhật lại
timestamptrong MongoDB collectionedu_lesson.process_checkpointsthành thời điểm của bản ghi cuối cùng đã xử lý, sẵn sàng cho lần chạy tiếp theo.
- Một quy trình được lên lịch (scheduled job), thực thi bởi script
-
Xử lý Tính toán Trạng thái Học tập (Dequeue Job):
- Một hoặc nhiều tiến trình xử lý (worker), thực thi bởi script
data_job_scheduler/job_dequeue.py, chạy liên tục hoặc định kỳ để lắng nghe (listen) hàng đợi trên Redis. - Lấy Tác vụ (Dequeue): Khi có tác vụ mới trong Redis queue, một worker sẽ lấy (dequeue) tác vụ đó ra để xử lý.
- Tính toán Trạng thái: Dựa trên thông tin trong tác vụ (tương tác mới nhất) và trạng thái học tập hiện tại của cặp (
profile_id,target) được lưu trữ trong MongoDB, worker này:- Truy vấn trạng thái hiện tại (nếu có) từ MongoDB collection
edu_backend.space_learning_data. - Áp dụng logic của thuật toán Spaced Repetition (dựa trên nguyên lý Ebbinghaus, có thể là biến thể như SM-2, FSRS, hoặc thuật toán tùy chỉnh của dự án) để cập nhật các tham số học tập. Các tham số này có thể bao gồm:
L: Mức độ thành thạo (Level) hoặc số lần ôn tập thành công liên tiếp.M: Hệ số nhân khoảng thời gian (Multiplier) hoặc Ease Factor.Q: Chất lượng của lần trả lời cuối cùng (Quality score).S: Độ ổn định (Stability) hoặc một chỉ số đo lường sức mạnh ghi nhớ.last_review: Thời điểm của lần tương tác/ôn tập cuối cùng (được cập nhật từ tác vụ).first_review: Thời điểm của lần tương tác đầu tiên (chỉ cập nhật lần đầu).
- Truy vấn trạng thái hiện tại (nếu có) từ MongoDB collection
- Cập nhật/Lưu Trạng thái: Worker lưu trạng thái học tập mới (hoặc tạo mới nếu chưa có) vào MongoDB collection
edu_backend.space_learning_data, sử dụngprofile_idvàtarget(hoặcword_id) làm khóa định danh. Dữ liệu lưu trữ có cấu trúc tương tự như sample bạn cung cấp:{ "_id": ObjectId(...), "profile_id": "6621089", "target": "Ellie", "word_id": 40126317, "L": 1, // Updated Level "M": 0, // Updated Multiplier/Ease "Q": 0, // Quality of this interaction "S": 10, // Updated Stability/Strength "created_at": ..., // First time this record was created "first_review": ..., // Timestamp of the very first interaction "last_review": ..., // Timestamp of this interaction (updated) "updated_at": ..., // Timestamp when this record was last modified "word_type": 1 // (or string type from input) }
- Một hoặc nhiều tiến trình xử lý (worker), thực thi bởi script
-
Output: Kết quả cuối cùng của giai đoạn này là collection
edu_backend.space_learning_datatrong MongoDB. Collection này chứa trạng thái học tập hiện tại và các tham số Spaced Repetition cho từng cặp người dùng-đơn vị kiến thức. Dữ liệu này là nền tảng để Giai đoạn 5 (Serving Layer) có thể tính toán hoặc truy vấn ra thời điểm ôn tập tiếp theo (next_review_timestamp) cho người dùng. Lưu ý:next_review_timestampcó thể không được lưu trực tiếp trong document này mà được tính toán động khi cần dựa trênlast_reviewvà các tham số nhưL,M,S.
Giai đoạn 5: Cung cấp Gợi ý Ôn tập cho Người dùng (Serving Layer)
- API: Một FastAPI endpoint (
POST /api/v1/load-review) được cung cấp để client lấy danh sách ôn tập. - Request: Client gửi
profile_idvàorder_unit(giới hạn unit muốn ôn tập). - Logic:
- API truy vấn MongoDB (
edu_backend.space_learning_data) lấy trạng thái học tập củaprofile_id. - Lọc các mục thuộc
unit <= order_unit(cần mapping word/unit). - Tính toán động thời điểm ôn tập tiếp theo (
next_review_timestamp) cho từng mục dựa trên các tham số SRS (L, M, S, last_review...). - Lọc lần cuối: Chỉ giữ lại các mục có
next_review_timestampđã đến hạn (<= thời gian hiện tại).
- API truy vấn MongoDB (
- Response: Trả về danh sách JSON các mục (
target,word_id, ...) cần ôn tập ngay.
Thông tin deployment:
CI/CD: Github Action
Serving on: Azure, vm-ai-machine-studio - 20.6.34.63