Tài liệu kĩ thuật và tích hợp AI M-Speak Dialogue
- Sơ đồ tổng quan các thành phần hệ thống
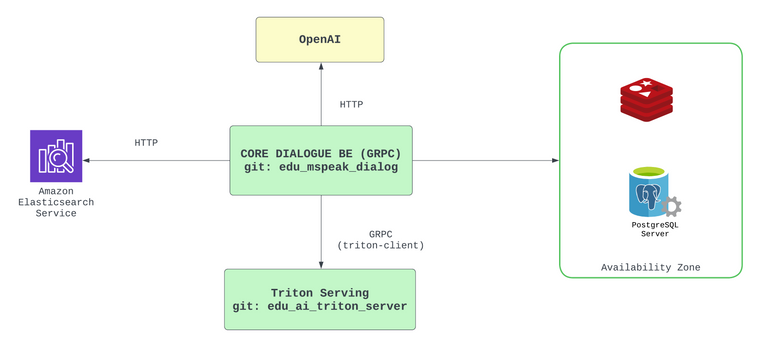
- Core Dialogue: Chịu trách nhiệm xử lý các logic nghiệp vụ của dialogue, và giao tiếp với các thành phần khác trong hệ thống. Là phương thức để app kết nối thông qua GRPC
- ELS: Logging và monitoring các thông số khi được xử lý
- Triton Serving: Là một service thực hiện inference các model AI phục vụ trong quá trình dialogue xảy ra.
- OpenAI: Third party phục vụ trong mục đích generate phản hồi cho người dùng.
- Postgres: Database chính của Dialogue
- Redis: Caching
- Các modules chính trong Core Dialogue BE
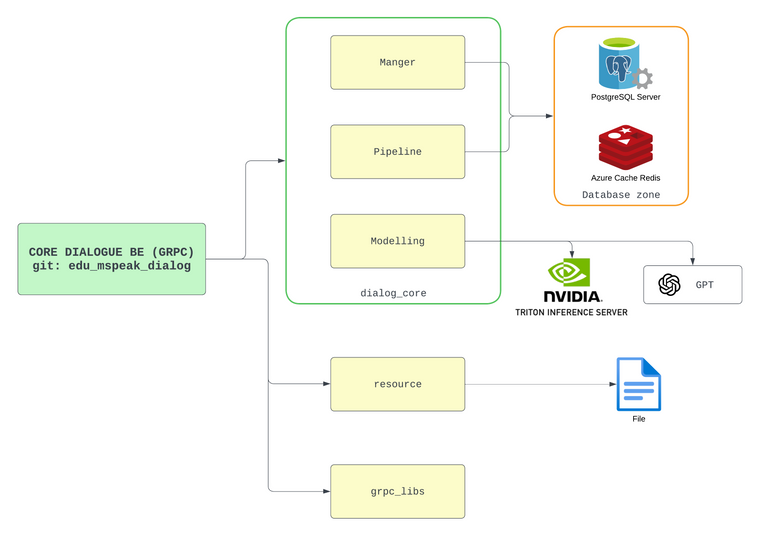
Trong Core BE Dialog gồm có 5 modules chính:
2.1 Manager
- Bao gồm các class tương tác với database thực hiện các thao tác: select, update, insert, delete tương ứng với từng bảng.
-> Toàn bộ được sử dụng thông qua factory_cls.py (Factory design patterns)
Chi tiết các bảng tương ứng các class tuân theo design database bên dưới.
2.2 Modeling
- Gồm các class hỗ trợ suy luận các mô hình AI extend triton_client -> được sử dụng thông qua factory_ai.py
- Các function đã được define sẵn sử dụng với OpenAI.
2.3 Pipeline:
Các pipeline cho dialogue gồm 3 pipeline chính:
- General pipeline: Toàn bộ câu trả lời người dùng sẽ đi qua pipeline này
- Response pipeline: Tuy theo các case người dùng sẽ được điều hướng vào 1 trong 3 pipeline tuỳ theo dạng câu hỏi người dùng đang trả lời là: Yes/No question, Media question hay Openning question.
- Answer pipeline: Generate câu phản hồi cho người dùng cùng với action tiếp theo của người dùng cần thực hiện.
Sử dụng thông qua factory_pipeline.py
2.4 Resouce
- Tập hợp các file bao gồm file config, các file yaml lưu trữ default các logic và câu trả lời mẫu.
- File proto của service
2.5 Grpc_libs:
- Define toàn bộ logic in/out của service khi kết nối với core.
- Thiết kế database
ER Diagram Description
tbl_conversation
| Column Name | Description |
|---|---|
| id | Primary key. |
| conversation_name | Name of the conversation. |
| description | Textual description of the conversation. |
| level | Level of the conversation. |
| voice | The type of voice used. |
| type | Conversation type (format/style). |
| num_tries | Number of tries allowed. |
| greeting | Greeting message/phrase. |
| greeting_media_url | URL to media file for the greeting. |
| ending | Ending message/phrase. |
| ending_media_url | URL to media file for the ending. |
| bundle_path | Path to the conversation's bundled files. |
| zip_path | Path to the zip file containing conversation data. |
| created_at | Record creation timestamp. |
| updated_at | Last record update timestamp. |
tbl_question
| Column Name | Description |
|---|---|
| id | Primary key. |
| conversation_id | Foreign key (links to tbl_conversation). |
| question | The question text. |
| media_url | URL to media file for the question. |
| index | The order/index of the question in conversation. |
| attribute_extend | Additional attributes/metadata. |
| created_at | Record creation timestamp. |
| updated_at | Last record update timestamp. |
| intent_condition | Conditions for intent applicability. |
tbl_intent
| Column Name | Description |
|---|---|
| id | Primary key. |
| question_id | Foreign key (links to tbl_question). |
| intent | The intent associated with the question. |
| response | Response text for the intent. |
| media_url | URL to media file for the response. |
| retrial | Number of retry attempts allowed. |
| created_at | Record creation timestamp. |
| updated_at | Last record update timestamp. |
Relationships:
- tbl_conversation: Has a one-to-many relationship with
tbl_questionviaconversation_id. - tbl_question: Has a one-to-many relationship with
tbl_intentviaquestion_id.
- Các chức năng chính trong service bao gồm:
UC1: Tạo mới một cuộc hội thoại
UC2: Tạo mới cuộc hội thoại bằng file (updating...)
UC3: Lấy danh sách các cuộc hội thoại
UC4: Điều khiển hội thoại (Answer Comunication Talk)
Để tạo mới một cuộc hội thoại cần chuẩn bị tên của hội thoại -> tương tứng với tên chủ đề.
Mỗi hội thoại bao gồm tập các câu hỏi và câu trả lời khác nhau.
Mỗi câu hỏi chỉ thuộc một trong 3 loại: Yes/No question, Media question, Opening question
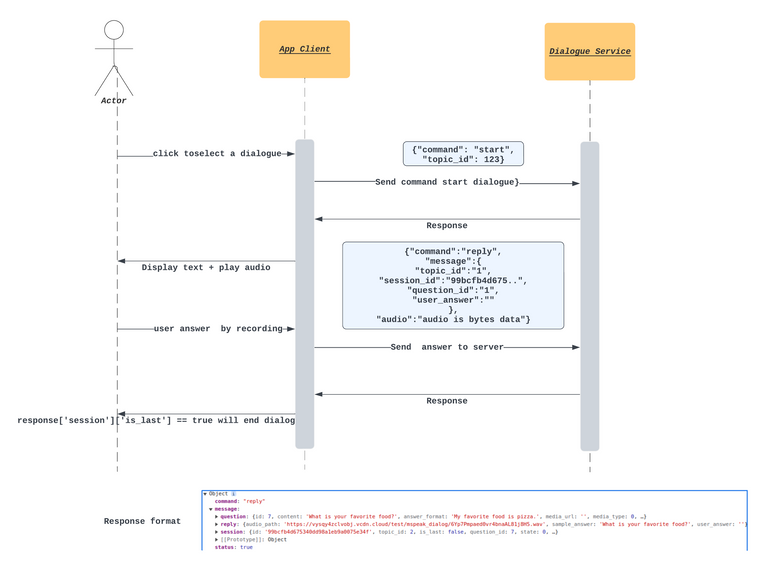
Flow tích hợp dialogue
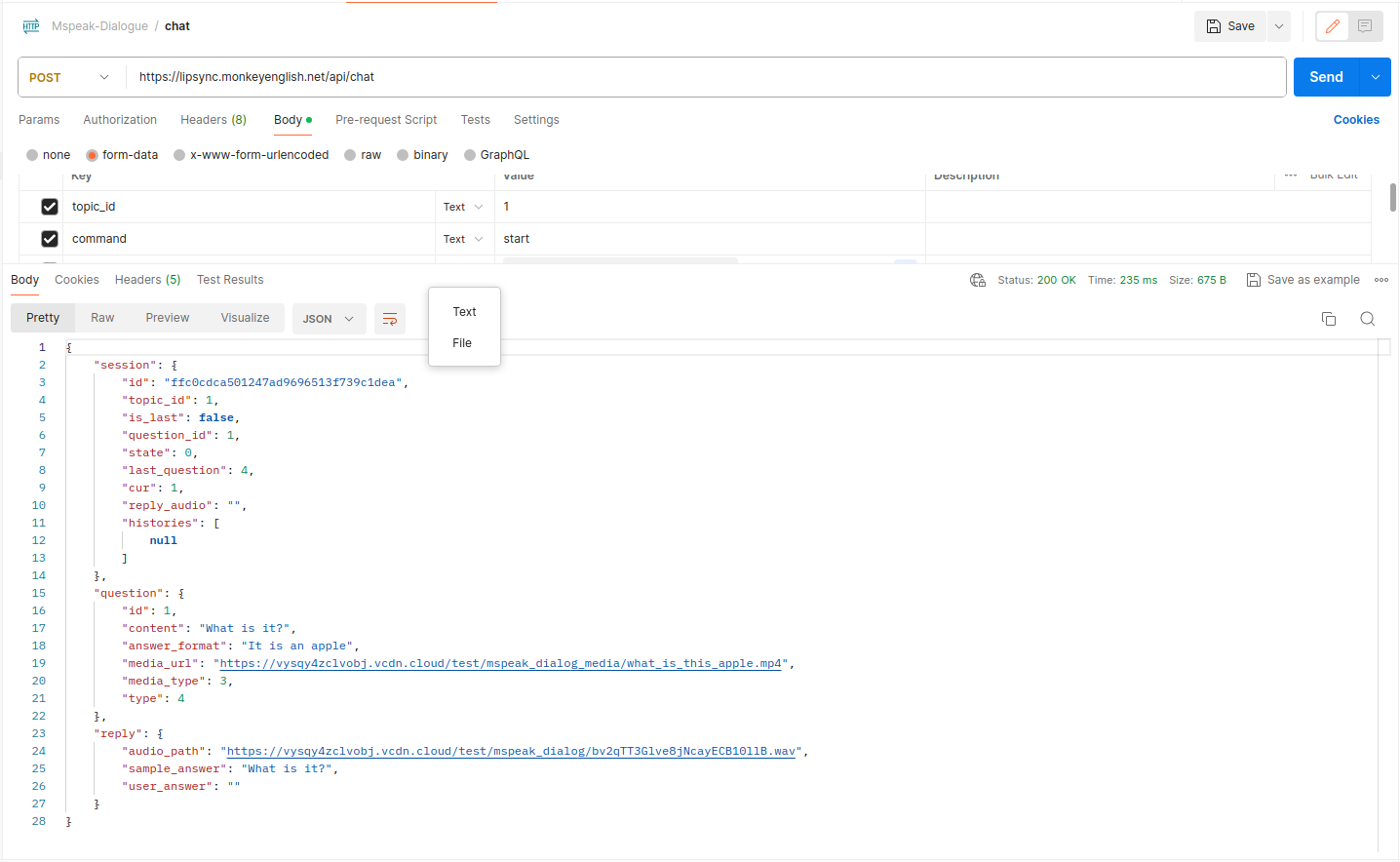
Postman document: Link
Bước 0: Khi người dùng chọn vào topic -> video introduction sẽ được play lên
B1: Khi hết intro video -> app gửi 1 request command start
Bước 2: Sau khi start thì hệ thống xác nhận một cuộc hội thoại mới và trả về một số thông tin
- session: thông tin về phiên làm việc của user, client quan tâm về session_id
- question: thông tin câu hỏi hiện tại của user
- reply: sẽ là câu phản hồi lại câu trả lời của người dùng. Nhưng do start thì câu đầu tiên nên người dùng sẽ chưa trả lời gì, vì vậy nên sẽ là câu hỏi bắt đầu luôn
Bước 3: Người dùng trả lời xong câu hỏi
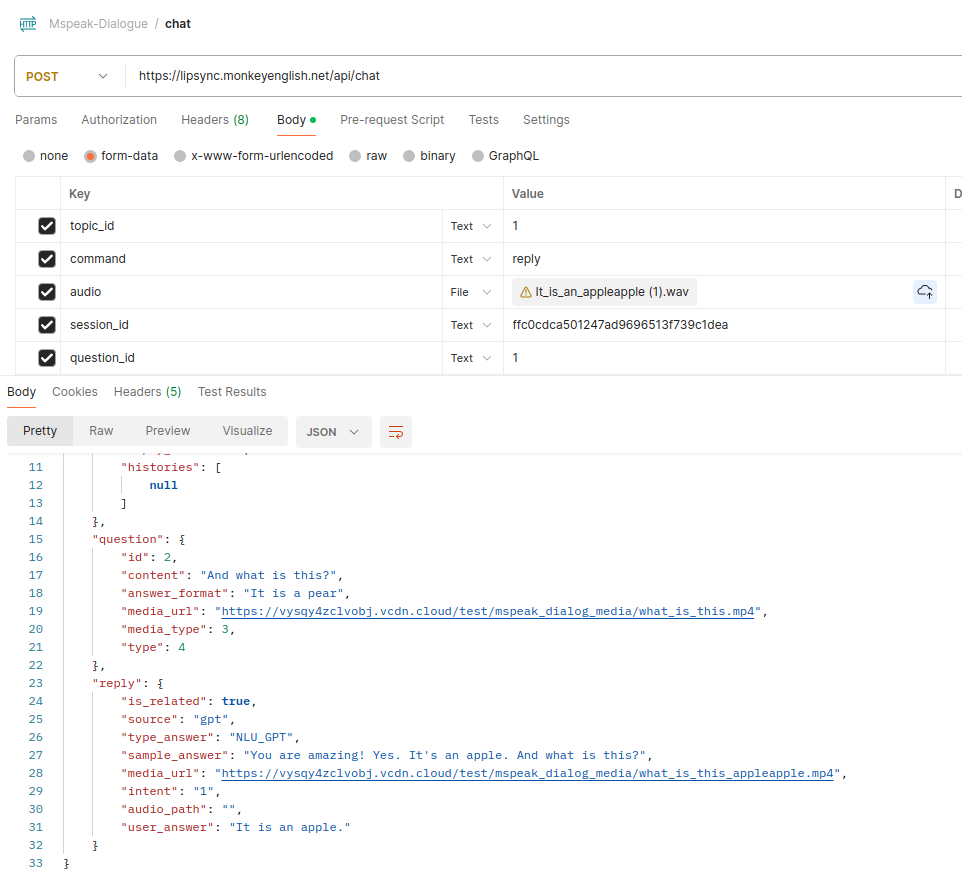
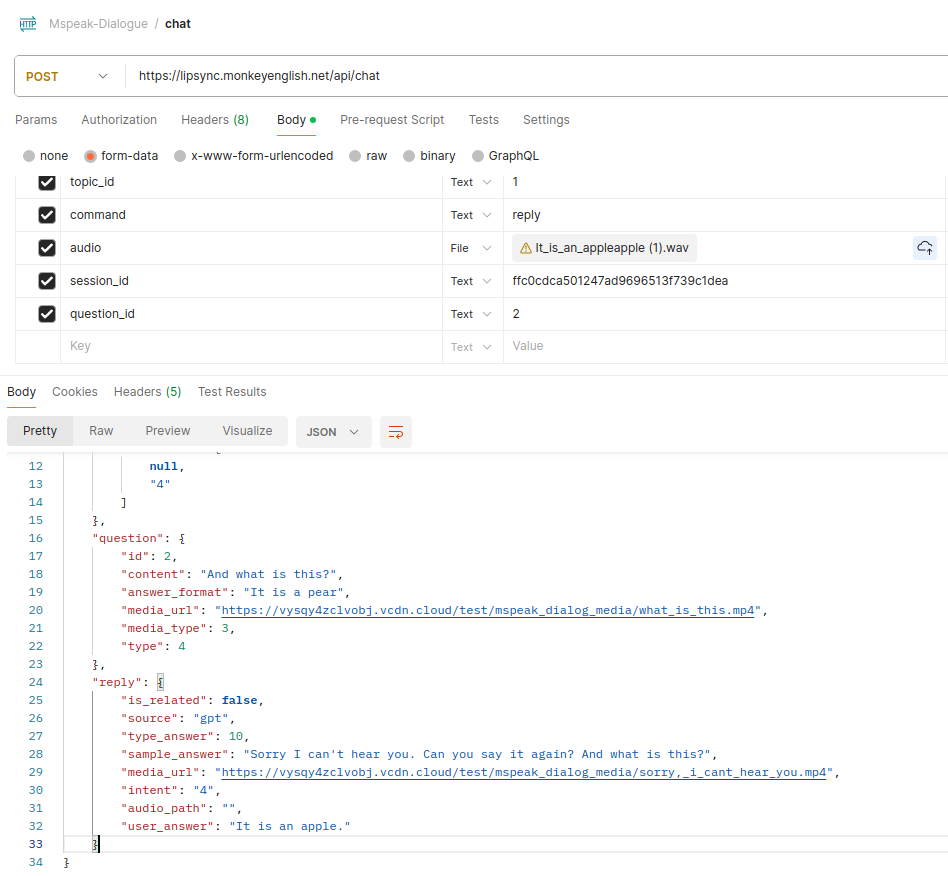
Bước 4: Lặp lại đến khi hết các câu
Trong session data nếu thấy "is_last": true, có nghĩa đó là câu cuối rồi. Thì sẽ không có câu hỏi nữa. Thì sẽ play video ending về.
WebSocket Client Usage Guide for Speech-Text
This document explains how to use a WebSocket client to send JSON data followed by audio data to a WebSocket server.
Prerequisites
Ensure you have the following prerequisites:
- A WebSocket server running and accessible.
- An audio file in WAV format (sample_rate = 16000, channels = 1)
Steps to Use the WebSocket Client
-
Prepare the Audio File:
- Ensure you have an audio file in WAV format that you want to send to the WebSocket server. (sample rate 16000, channels = 1)
-
Connect to the WebSocket Server:
- Establish a connection to the WebSocket server using the server's URI (Uniform Resource Identifier). The URI typically includes the protocol (ws or wss), the server's address, and the endpoint for the WebSocket connection. For example:
ws://localhost:8000/ws/{device_id}
- Establish a connection to the WebSocket server using the server's URI (Uniform Resource Identifier). The URI typically includes the protocol (ws or wss), the server's address, and the endpoint for the WebSocket connection. For example:
Domain dev: wss://lipsync.monkeyenglish.net/ws/{device_id}
Domain live: wss://videocall.monkeyenglish.net/ws/{device_id}
Note: device_id is a unique string, can use profile Id, or others
-
Send Audio Data:
- Read the audio data from the WAV file and send it as binary data to the WebSocket server. Make sure the audio data is sent after the JSON message.
-
Send JSON Data:
- Send a JSON message containing the context of the speech. The JSON data should have a key named
contextand the value should be the text describing the context. For example:{ "context": "This is a test context for speech-to-text conversion." } - Ensure the JSON message is sent first before sending the audio data.
- Context is question, topic type or anything to scale scope of audio input -> prefer inserting question
- Send a JSON message containing the context of the speech. The JSON data should have a key named
-
Receive the Response:
- Wait for the WebSocket server to process the data and send a response. The response could be the result of the speech-to-text conversion or any other relevant information.
Example response:
{"text": "They are very beautiful"}
- Wait for the WebSocket server to process the data and send a response. The response could be the result of the speech-to-text conversion or any other relevant information.
-
Handle Disconnection:
- Be prepared to handle disconnections from the WebSocket server gracefully. Ensure that any resources or connections are properly closed.
Example Workflow
- Connect to the WebSocket server at
ws://localhost:8000/ws/{device_id}. - Send JSON data with the key
contextand a relevant value. - Send audio data from a WAV file.
- Receive and process the server's response.
- Close the connection gracefully.
Notes
- Ensure that the audio data is in the correct format (e.g.,
float32) before sending it. - If an error occurs during the process, handle it appropriately and attempt to reconnect if necessary.
- The WebSocket server should be configured to handle both JSON and binary data correctly.